本文來自格隆匯專欄:中金研究,作者:於鍾海 王之昊 等
2023年4月5日,Meta發佈通用的圖像大模型Segment Anything Model(SAM),是一個可以接受文本提示、基於海量數據訓練而獲得泛化能力、可以對任意圖片進行分割的模型。基於網絡上的大規模數據訓練出來的自然語言模型正在革新AI行業,SAM的出現代表計算機視覺領域(CV)出現類ChatGPT突破,通過提示工程可以解決不同的下游分割任務,我們認為CV應用相關產業趨勢值得關注。
摘要
SAM實現了圖像分割這一計算機視覺領域重要任務,具備多個設計亮點。圖像分割的重要性體現在對象識別、對象檢測、圖像編輯、醫學成像、便利下游任務等功能中。SAM融合了提示學習技術靈活地實現模型構建,通過交互註釋構建圖像引擎,在實例分析、邊緣檢測、物體提議、文字到掩膜等技術方面表現較好,但在其他項目具有侷限性。儘管SAM的數據集已經開源,但僅供研究使用,不可商用。
我們認為SAM有望引領元宇宙概念的再次興起。我們認為未來算力提升後的SAM模型將實現MR、XR場景下的交互,成為元宇宙和諸多領域在用户交互的基礎能力。隨蘋果MR設備的發佈,元宇宙或迎來再次興起。
技術突破可能帶來CV應用的持續滲透。CV能力的增強利好整體CV行業應用的滲透,獲得用户的認可與用户支出的傾斜。我們認為未來需要關注CV領域應用,如自動駕駛、安防和智慧城市、家庭用攝像頭和機器人、工業質檢和工業視覺、MR和XR等,及數據標註、基礎算法等其他領域應用。
風險
技術進展不及預期,行業競爭加劇,商業化落地節奏不及預期。
Segment Anything簡介
Segment Anything Model(以下簡稱“SAM”)為Meta最新成果。在這篇論文中,Meta構建了一個可以對任意圖片進行分割的模型,並根據模型提供了一個高質量的10億掩模圖片數據集(SA-1B)。
基於網絡上的大規模數據訓練出來的自然語言模型(“LLM”)正在革新AI行業,其具備較強的零樣本學習(Zero-shot)和小樣本學習(Few-shot)學習能力,是泛化的通用模型。在自然語言領域,我們已經見證了GPT-4、LLAMA等多個知名模型具備上述的強大能力。但在計算機視覺領域(“CV”),相關的研究較少。CLIP和ALIGN兩個將文本和圖像連接起來的模型是這一領域亮眼的工作。基於CLIP,OpenAI進一步開發了DALL.E系列模型,將文本提示(“Prompt”)直接轉換為圖像,Demo如鏈接:https://segment-anything.com/demo。
SAM模型建立了一個可以接受文本提示、基於海量數據訓練而獲得泛化能力的圖像分割大模型。在SAM基模型之上,通過提示工程後可以解決不同的下游分割任務。根據官方的能力説明,SAM可以完成如下任務:
► SAM允許用户通過單擊或交互式單擊要包括和排除的點來分割對象。該模型還可以通過邊界框提示。
►當面臨分割對象的模糊性時,SAM可以輸出多個有效的遮罩,這是解決實際分割問題的重要而必要的能力。
►SAM可以自動查找並遮罩圖像中的所有對象。
►SAM可以在預計算圖像嵌入之後,實時為任何提示生成分割遮罩,從而允許與模型進行實時交互。
圖表1:通過鼠標的懸停,可以選中任意一個物體分割出來;或者通過鼠標圈選一個框,可以提取框中的所有物體。

資料來源:MetaAI,中金公司研究部
圖表2:使用Everything功能可以直接提取所有的物體,並在cut-outs裏面看到它們

資料來源:MetaAI,中金公司研究部
什麼是圖像分割,為什麼要圖像分割?
圖像分割是計算機視覺中的一項重要任務,它涉及到將圖像劃分為多個區域或片段,每個區域或片段代表圖像的一個有意義的部分。圖像分割的重要性主要表現在下列功能上:
► 對象識別:圖像分割有助於識別和確認圖像中的不同物體。通過將圖像分為不同的區段,每個區段都可以被單獨分析,從而更容易識別物體和它們的屬性。
► 對象檢測:圖像分割也可以幫助檢測圖像中的物體,把它們從背景中分離出來。這在自動駕駛等應用中特別有用,自動駕駛汽車需要檢測其他汽車、行人和障礙物。
► 圖像編輯:圖像分割是許多圖像編輯任務中的一個重要步驟,如去除物體、顏色校正和圖像合成。通過將圖像劃分為不同的片段,單個片段可以被修改而不影響圖像的其他部分。
► 醫學成像:在醫學成像中,圖像分割被用來從醫學圖像中提取特定結構或潛在病灶存在的區域。這可以幫助診斷、治療計劃和監測各種疾病。
► 便利下游任務:圖像分割的下游工作包括物體識別、物體檢測、物體跟蹤、圖像修復、圖像分類和許多其他計算機視覺任務。這些任務需要準確和有效的圖像分割作為預處理步驟,以便從圖像中提取有意義的信息。
Segment Anything Model的設計亮點
SAM的基礎架構包含三個關鍵部分:可提示的分割任務,SAM模型,以及一個超過1100萬張照片、超過10億的掩膜(Mask,指分割出來的結果)的數據集。
圖表3:SAM的基礎架構包含三個關鍵部分
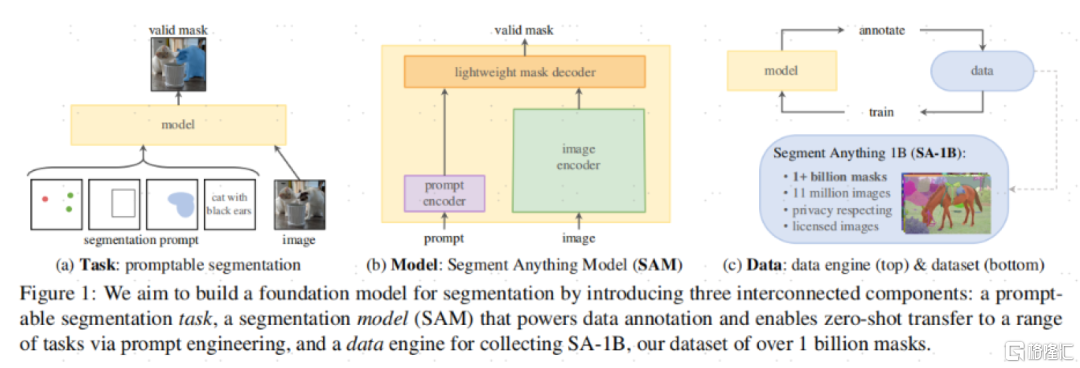
資料來源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
任務定義:SAM融合了提示學習技術——NLP領域已經大規模的使用了提示學習技術,MetaAI團隊嘗試將NLP領域的提示翻譯為文本分割領域的提示。在文本分割領域,MetaAI定義的一個提示可以是一個勾選框、一個點或者自然語言。
模型構建:SAM需要同時滿足三個限制:1)靈活的提示;2)實時計算掩膜;3)支持模糊的感知能力。而SAM模型通過一個圖像編碼器(image encoder)和一個快速提示編碼器/掩膜解碼器(Fast prompt encoder/mask decoder)更好地解決了這個問題。
SAM具備高效靈活的模型設計。在打開圖片使用後,僅需0.15秒可計算出圖片的嵌入(Embeddings), 之後在網頁上用CPU處理,在0.55秒內即可對文本提示/掩膜進行輕量化的編碼/解碼。
圖表4:SAM具備高效靈活的模型設計
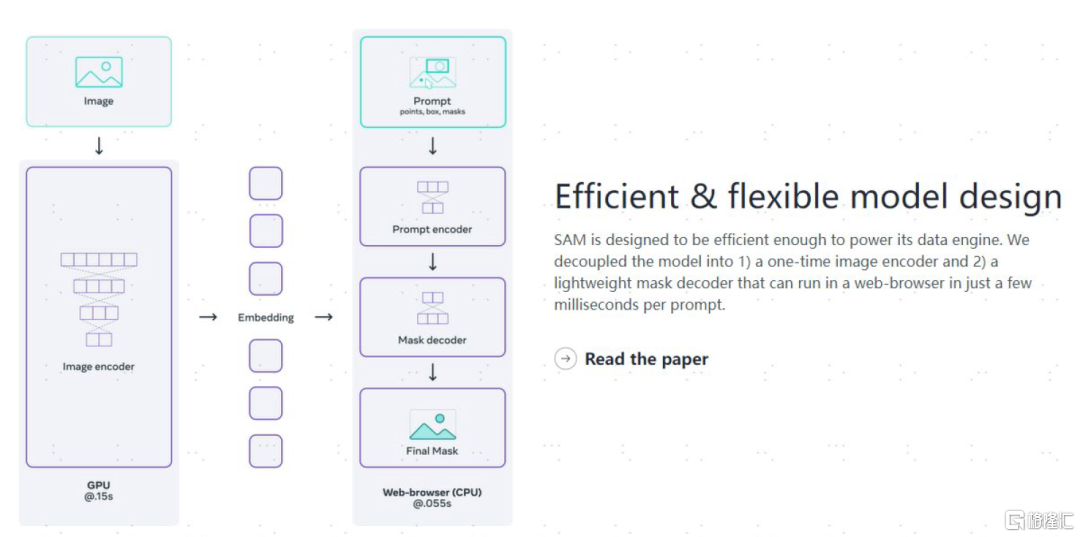
資料來源:MetaAI Blog,中金公司研究部
圖像引擎:為了實現模型的強大泛化能力(可以在Zero-shot基礎上識別各種物體),SAM的訓練需要龐大的分割過的圖像數據,然而目前並沒有這麼豐富的數據集。因此MetaAI建立了一個Data engine。在第一階段,SAM幫助標註人員來進行掩膜的標註;在第二階段,訓練人員目標於增加物體的多樣性,以幫助SAM可以標註各種物體。此時,SAM可以自動標註一批物體,而標註人員只要標註其他的部分即可;在最終階段,通過在圖片上施加一個點組成的矩陣來識別,SAM可以自動在一個圖片上平均每張產生~100個高質量的掩膜。
注意,這個模型的訓練過程還是需要專業的標註人員。但是通過交互式的註釋,在第一階段一個掩碼標註平均只需要14秒時間(比COCO掩碼標註快6.5倍)。
圖表5:SAM模型進行圖像分割的示例,來自SA-1B

資料來源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
模型訓練的成本
模型訓練過程中,Meta從一位版權圖片提供商處獲得了圖片,具體的費用未被披露。在訓練過程中,Meta使用了256張英偉達A100 GPU訓練了68小時,相對成本並不算高昂。
模型的侷限性
SAM模型在Zero-shot的點擊物體生成對應掩膜(點擊一下物體,即可把它提取出來),以及邊緣檢測、物品發現、實例分割等項目上都有很好的表現。但在Zero-shot文字到掩膜上表現一般,有時候需要人類給一個點的提示,可能表現會更好一些。MetaAI團隊在論文中也承認這邊的探索仍有更多的工作可以做。
圖表6:SAM模型表現較好的項目

資料來源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
圖表7:用文字要求SAM找到雨刷(Wipers),可能會失敗;但是如果給一個點的提示,它能夠找到一個完整的雨刷,甚至觸類旁通找到旁邊的雨刷

資料來源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
SAM模型儘管表現較好,但對於垂類領域的專用模型來説,可能在精度上表現不佳。與此同時,對於一些小的連接件,可能會錯誤的標註出來。在邊緣的精度上,也沒有一些算力需求更大的算法那麼精細。
圖表8:SAM模型將柯基的項圈也分割了出來

資料來源:MetaAI,中金公司研究部
許可和限制
SAM模型本體為Apache 2.0協議,為寬鬆協議,可商用,可修改。雖然一般Meta都會額外要求不可商用,但我們目前還沒看到相關的條款。論文中註明 ,SA-1B數據集在Apache 2.0許可證下開源,但僅供研究使用,項目地址如鏈接。
圖表9:SA-1B數據集不可商用,僅供研究使用
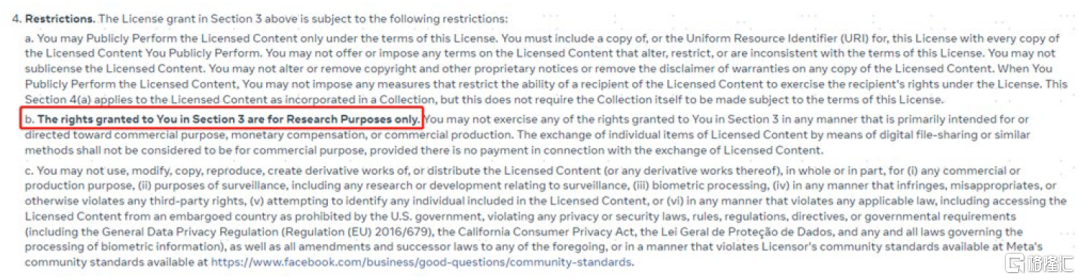
資料來源:MetaAI,中金公司研究部
未來展望:潛在用例和影響
一個識別各種物體的通用CV模型要出現了?
儘管目前SAM模型的文字到掩膜能力尚未臻於完善,但是可能我們距離一個能夠識別,並且知道自己識別了什麼物體的通用模型是否更近了一步?這可能是有些人認為CV將不存在的原因。
圖表10:SAM模型的文字到掩膜案例
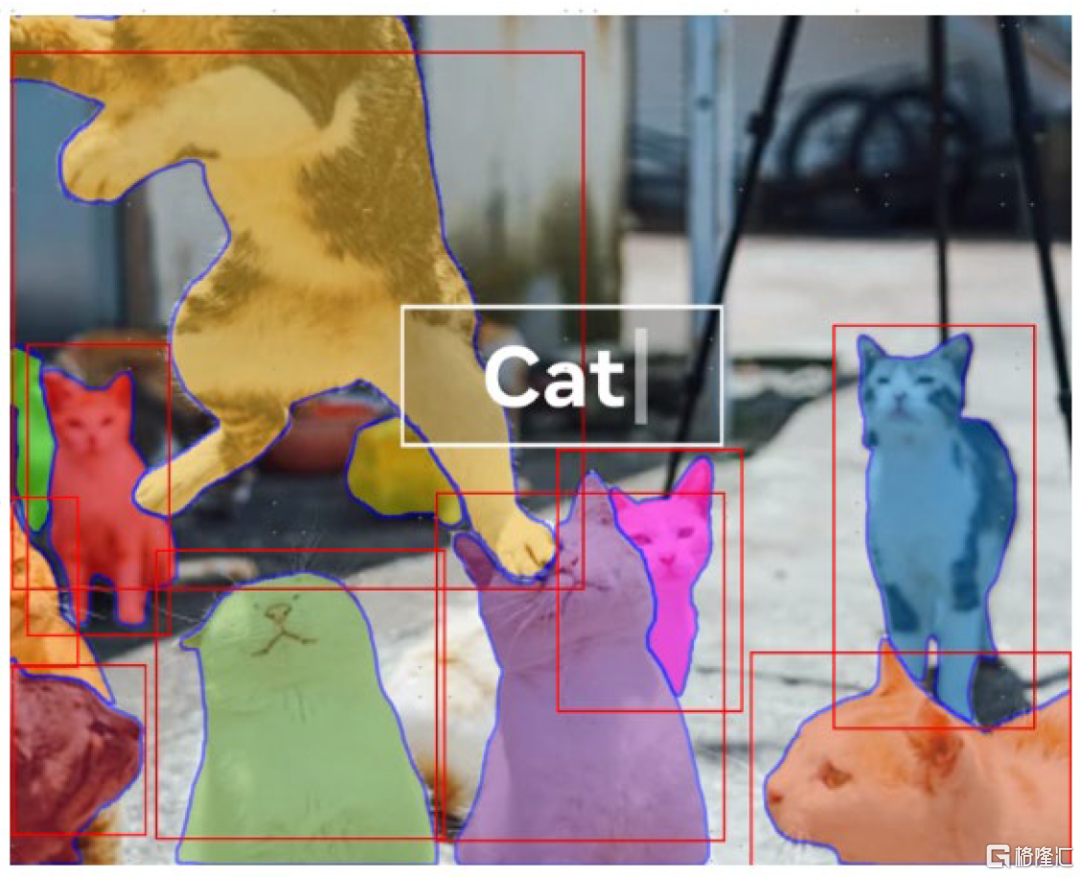
資料來源:MetaAI,中金公司研究部
元宇宙概念的再次興起
算力提升後的SAM模型將成為元宇宙和諸多領域在用户交互上的基礎能力。Meta在元宇宙上投入頗豐,我們預計,未來SAM算法有望根據用户的目光跟蹤,隨時注意到用户正在觀察的物體,成為MR、XR場景下非常重要的基礎交互能力。若進一步打開想象,當我們手指物體,命令機器人或者攝像頭“把那個打開/拿給我”,機器人或者攝像頭也能相應理解我們的意思。元宇宙的到來(聚焦於XR和三維化)可能比每個人想象的都快。我們認為,跟隨蘋果MR設備的發佈,元宇宙可能迎來再次興起的熱潮。
CV應用的持續滲透
CV能力的增強,利好整體CV行業應用的滲透,CV的能力越強,相關的應用就能更加的獲得用户的認可,獲得用户支出的傾斜。可以概括為:有攝像頭的場景都可能成為受益場景。在自動駕駛領域,CV應用有利於加速數據標註,加速算法迭代,更快擁抱L5級自動駕駛的誕生。在C端應用領域,將提供更豐富的功能,提升用户粘性和價值。
其他領域
數據標註:SAM的算法對於數據標註行業的影響顯而易見,我們預計把握先機的龍頭企業將繼續憑藉R&D優勢衝擊中小長尾企業。
基礎算法:對於CV基礎算法企業,來自海外大廠和開源的競爭愈發明顯,我們認為行業集中度將逐漸提升,需要關注領先大廠。
MLOps(人工智能研發運營一體化,Machine Learning Operations):旨在統一機器學習系統開發和系統部署,通過標準化過程持續交付高性能模型。隨着CV和NLP的發展,MLOps均會受益。
注:本文摘自中金公司2023年4月9日已經發布的《中金前沿論文導讀:Segment Anything,CV領域新進展》,報吿分析師:
於鍾海 分析員 SAC 執證編號:S0080518070011 SFC CE Ref:BOP246
王之昊 分析員 SAC 執證編號:S0080522050001 SFC CE Ref:BSS168
魏鸛霏 聯繫人 SAC 執證編號:S0080121070252 SFC CE Ref:BSX734