本文来自格隆汇专栏:中金研究,作者:于钟海 王之昊 等
2023年4月5日,Meta发布通用的图像大模型Segment Anything Model(SAM),是一个可以接受文本提示、基于海量数据训练而获得泛化能力、可以对任意图片进行分割的模型。基于网络上的大规模数据训练出来的自然语言模型正在革新AI行业,SAM的出现代表计算机视觉领域(CV)出现类ChatGPT突破,通过提示工程可以解决不同的下游分割任务,我们认为CV应用相关产业趋势值得关注。
摘要
SAM实现了图像分割这一计算机视觉领域重要任务,具备多个设计亮点。图像分割的重要性体现在对象识别、对象检测、图像编辑、医学成像、便利下游任务等功能中。SAM融合了提示学习技术灵活地实现模型构建,通过交互注释构建图像引擎,在实例分析、边缘检测、物体提议、文字到掩膜等技术方面表现较好,但在其他项目具有局限性。尽管SAM的数据集已经开源,但仅供研究使用,不可商用。
我们认为SAM有望引领元宇宙概念的再次兴起。我们认为未来算力提升后的SAM模型将实现MR、XR场景下的交互,成为元宇宙和诸多领域在用户交互的基础能力。随苹果MR设备的发布,元宇宙或迎来再次兴起。
技术突破可能带来CV应用的持续渗透。CV能力的增强利好整体CV行业应用的渗透,获得用户的认可与用户支出的倾斜。我们认为未来需要关注CV领域应用,如自动驾驶、安防和智慧城市、家庭用摄像头和机器人、工业质检和工业视觉、MR和XR等,及数据标注、基础算法等其他领域应用。
风险
技术进展不及预期,行业竞争加剧,商业化落地节奏不及预期。
Segment Anything简介
Segment Anything Model(以下简称“SAM”)为Meta最新成果。在这篇论文中,Meta构建了一个可以对任意图片进行分割的模型,并根据模型提供了一个高质量的10亿掩模图片数据集(SA-1B)。
基于网络上的大规模数据训练出来的自然语言模型(“LLM”)正在革新AI行业,其具备较强的零样本学习(Zero-shot)和小样本学习(Few-shot)学习能力,是泛化的通用模型。在自然语言领域,我们已经见证了GPT-4、LLAMA等多个知名模型具备上述的强大能力。但在计算机视觉领域(“CV”),相关的研究较少。CLIP和ALIGN两个将文本和图像连接起来的模型是这一领域亮眼的工作。基于CLIP,OpenAI进一步开发了DALL.E系列模型,将文本提示(“Prompt”)直接转换为图像,Demo如链接:https://segment-anything.com/demo。
SAM模型建立了一个可以接受文本提示、基于海量数据训练而获得泛化能力的图像分割大模型。在SAM基模型之上,通过提示工程后可以解决不同的下游分割任务。根据官方的能力说明,SAM可以完成如下任务:
► SAM允许用户通过单击或交互式单击要包括和排除的点来分割对象。该模型还可以通过边界框提示。
►当面临分割对象的模糊性时,SAM可以输出多个有效的遮罩,这是解决实际分割问题的重要而必要的能力。
►SAM可以自动查找并遮罩图像中的所有对象。
►SAM可以在预计算图像嵌入之后,实时为任何提示生成分割遮罩,从而允许与模型进行实时交互。
图表1:通过鼠标的悬停,可以选中任意一个物体分割出来;或者通过鼠标圈选一个框,可以提取框中的所有物体。

资料来源:MetaAI,中金公司研究部
图表2:使用Everything功能可以直接提取所有的物体,并在cut-outs里面看到它们

资料来源:MetaAI,中金公司研究部
什么是图像分割,为什么要图像分割?
图像分割是计算机视觉中的一项重要任务,它涉及到将图像划分为多个区域或片段,每个区域或片段代表图像的一个有意义的部分。图像分割的重要性主要表现在下列功能上:
► 对象识别:图像分割有助于识别和确认图像中的不同物体。通过将图像分为不同的区段,每个区段都可以被单独分析,从而更容易识别物体和它们的属性。
► 对象检测:图像分割也可以帮助检测图像中的物体,把它们从背景中分离出来。这在自动驾驶等应用中特别有用,自动驾驶汽车需要检测其他汽车、行人和障碍物。
► 图像编辑:图像分割是许多图像编辑任务中的一个重要步骤,如去除物体、颜色校正和图像合成。通过将图像划分为不同的片段,单个片段可以被修改而不影响图像的其他部分。
► 医学成像:在医学成像中,图像分割被用来从医学图像中提取特定结构或潜在病灶存在的区域。这可以帮助诊断、治疗计划和监测各种疾病。
► 便利下游任务:图像分割的下游工作包括物体识别、物体检测、物体跟踪、图像修复、图像分类和许多其他计算机视觉任务。这些任务需要准确和有效的图像分割作为预处理步骤,以便从图像中提取有意义的信息。
Segment Anything Model的设计亮点
SAM的基础架构包含三个关键部分:可提示的分割任务,SAM模型,以及一个超过1100万张照片、超过10亿的掩膜(Mask,指分割出来的结果)的数据集。
图表3:SAM的基础架构包含三个关键部分
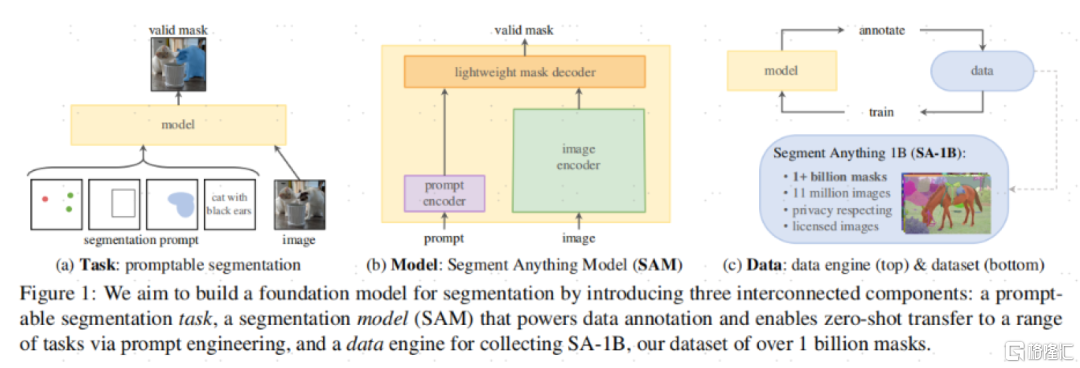
资料来源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
任务定义:SAM融合了提示学习技术——NLP领域已经大规模的使用了提示学习技术,MetaAI团队尝试将NLP领域的提示翻译为文本分割领域的提示。在文本分割领域,MetaAI定义的一个提示可以是一个勾选框、一个点或者自然语言。
模型构建:SAM需要同时满足三个限制:1)灵活的提示;2)实时计算掩膜;3)支持模糊的感知能力。而SAM模型通过一个图像编码器(image encoder)和一个快速提示编码器/掩膜解码器(Fast prompt encoder/mask decoder)更好地解决了这个问题。
SAM具备高效灵活的模型设计。在打开图片使用后,仅需0.15秒可计算出图片的嵌入(Embeddings), 之后在网页上用CPU处理,在0.55秒内即可对文本提示/掩膜进行轻量化的编码/解码。
图表4:SAM具备高效灵活的模型设计
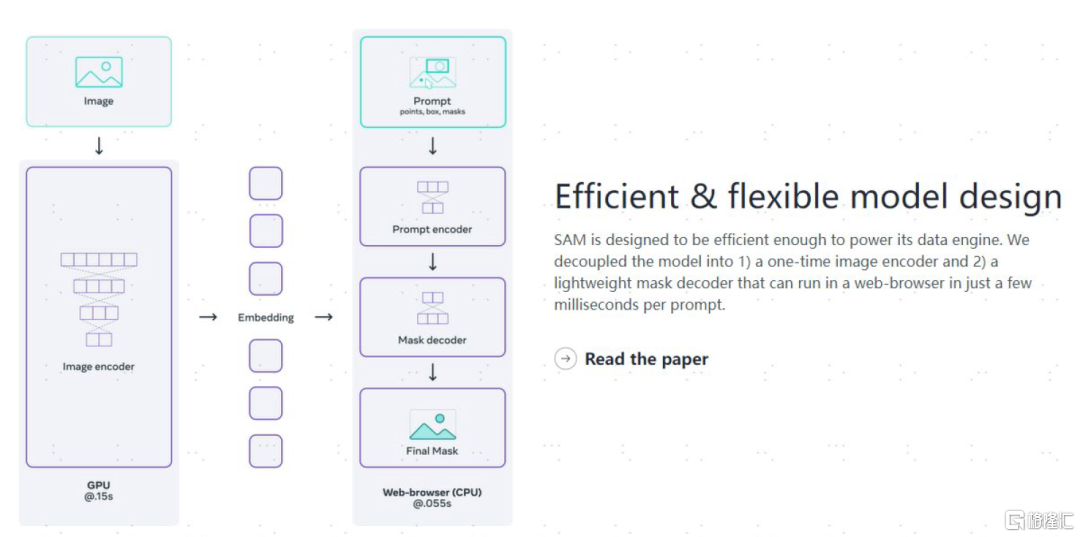
资料来源:MetaAI Blog,中金公司研究部
图像引擎:为了实现模型的强大泛化能力(可以在Zero-shot基础上识别各种物体),SAM的训练需要庞大的分割过的图像数据,然而目前并没有这么丰富的数据集。因此MetaAI建立了一个Data engine。在第一阶段,SAM帮助标注人员来进行掩膜的标注;在第二阶段,训练人员目标于增加物体的多样性,以帮助SAM可以标注各种物体。此时,SAM可以自动标注一批物体,而标注人员只要标注其他的部分即可;在最终阶段,通过在图片上施加一个点组成的矩阵来识别,SAM可以自动在一个图片上平均每张产生~100个高质量的掩膜。
注意,这个模型的训练过程还是需要专业的标注人员。但是通过交互式的注释,在第一阶段一个掩码标注平均只需要14秒时间(比COCO掩码标注快6.5倍)。
图表5:SAM模型进行图像分割的示例,来自SA-1B

资料来源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
模型训练的成本
模型训练过程中,Meta从一位版权图片提供商处获得了图片,具体的费用未被披露。在训练过程中,Meta使用了256张英伟达A100 GPU训练了68小时,相对成本并不算高昂。
模型的局限性
SAM模型在Zero-shot的点击物体生成对应掩膜(点击一下物体,即可把它提取出来),以及边缘检测、物品发现、实例分割等项目上都有很好的表现。但在Zero-shot文字到掩膜上表现一般,有时候需要人类给一个点的提示,可能表现会更好一些。MetaAI团队在论文中也承认这边的探索仍有更多的工作可以做。
图表6:SAM模型表现较好的项目

资料来源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
图表7:用文字要求SAM找到雨刷(Wipers),可能会失败;但是如果给一个点的提示,它能够找到一个完整的雨刷,甚至触类旁通找到旁边的雨刷

资料来源:《Segment Anything》(Kirillov et al., 2023),中金公司研究部
SAM模型尽管表现较好,但对于垂类领域的专用模型来说,可能在精度上表现不佳。与此同时,对于一些小的连接件,可能会错误的标注出来。在边缘的精度上,也没有一些算力需求更大的算法那么精细。
图表8:SAM模型将柯基的项圈也分割了出来

资料来源:MetaAI,中金公司研究部
许可和限制
SAM模型本体为Apache 2.0协议,为宽松协议,可商用,可修改。虽然一般Meta都会额外要求不可商用,但我们目前还没看到相关的条款。论文中注明 ,SA-1B数据集在Apache 2.0许可证下开源,但仅供研究使用,项目地址如链接。
图表9:SA-1B数据集不可商用,仅供研究使用
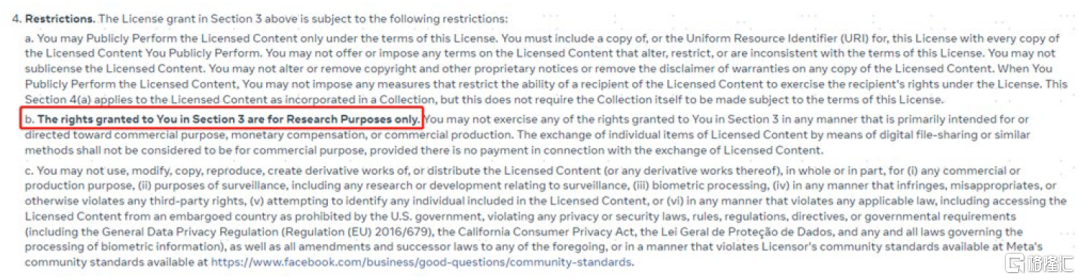
资料来源:MetaAI,中金公司研究部
未来展望:潜在用例和影响
一个识别各种物体的通用CV模型要出现了?
尽管目前SAM模型的文字到掩膜能力尚未臻于完善,但是可能我们距离一个能够识别,并且知道自己识别了什么物体的通用模型是否更近了一步?这可能是有些人认为CV将不存在的原因。
图表10:SAM模型的文字到掩膜案例
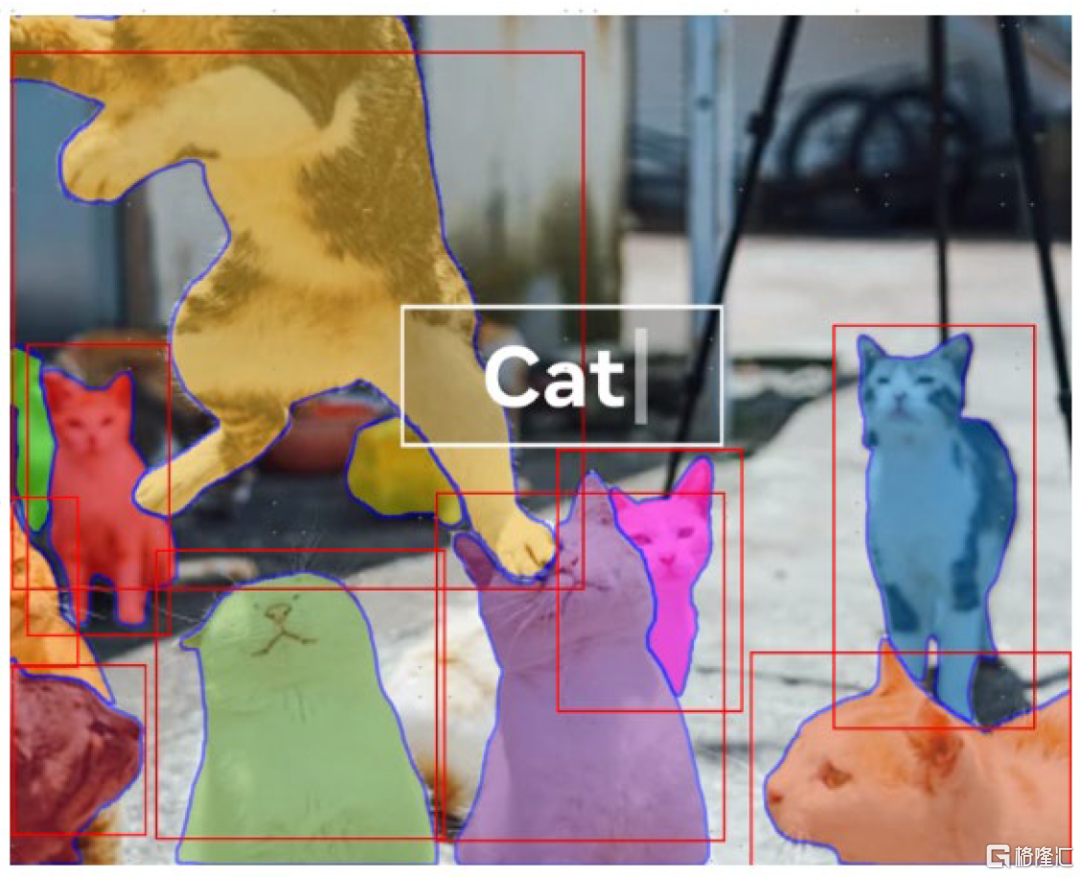
资料来源:MetaAI,中金公司研究部
元宇宙概念的再次兴起
算力提升后的SAM模型将成为元宇宙和诸多领域在用户交互上的基础能力。Meta在元宇宙上投入颇丰,我们预计,未来SAM算法有望根据用户的目光跟踪,随时注意到用户正在观察的物体,成为MR、XR场景下非常重要的基础交互能力。若进一步打开想象,当我们手指物体,命令机器人或者摄像头“把那个打开/拿给我”,机器人或者摄像头也能相应理解我们的意思。元宇宙的到来(聚焦于XR和三维化)可能比每个人想象的都快。我们认为,跟随苹果MR设备的发布,元宇宙可能迎来再次兴起的热潮。
CV应用的持续渗透
CV能力的增强,利好整体CV行业应用的渗透,CV的能力越强,相关的应用就能更加的获得用户的认可,获得用户支出的倾斜。可以概括为:有摄像头的场景都可能成为受益场景。在自动驾驶领域,CV应用有利于加速数据标注,加速算法迭代,更快拥抱L5级自动驾驶的诞生。在C端应用领域,将提供更丰富的功能,提升用户粘性和价值。
其他领域
数据标注:SAM的算法对于数据标注行业的影响显而易见,我们预计把握先机的龙头企业将继续凭借R&D优势冲击中小长尾企业。
基础算法:对于CV基础算法企业,来自海外大厂和开源的竞争愈发明显,我们认为行业集中度将逐渐提升,需要关注领先大厂。
MLOps(人工智能研发运营一体化,Machine Learning Operations):旨在统一机器学习系统开发和系统部署,通过标准化过程持续交付高性能模型。随着CV和NLP的发展,MLOps均会受益。
注:本文摘自中金公司2023年4月9日已经发布的《中金前沿论文导读:Segment Anything,CV领域新进展》,报吿分析师:
于钟海 分析员 SAC 执证编号:S0080518070011 SFC CE Ref:BOP246
王之昊 分析员 SAC 执证编号:S0080522050001 SFC CE Ref:BSS168
魏鹳霏 联系人 SAC 执证编号:S0080121070252 SFC CE Ref:BSX734