本文來自格隆匯專欄:中金研究;作者:彭虎 成喬升等
我們認為,通用人工智能能力的湧現、生成式AI應用的商業落地均離不開雲端AI算力芯片支撐。目前,雲端AI算力芯片滲透率僅為個位數,未來成長空間廣闊。GPU最初作為圖形計算芯片,在過去十餘年的發展中不斷迭代升級,逐漸在並行計算、AI智能計算、科學計算等領域嶄露頭角並獲得廣泛認可。與此同時,定製化架構的AI算力芯片(如ASIC)也像雨後春筍一般層出不窮,以其性價比、能耗比等優勢在AI應用領域取得一席之地。
摘要
全功能GPU是目前主流AI算力芯片:兼具通用性和高性能計算的全功能GPU仍然是當下AI算力芯片的最主流形態,可適應未來大模型多模態發展需求。GPU架構中頂點、像素着色器結構天生適合並行計算,可編程的特點促使GPU加速進入AI算力市場。目前,GPU也增加了定製化的張量計算單元來滿足日益增長的AI算力需求。由於AI模型的算子及結構仍處於快速迭代期,而硬件芯片的設計需要與算法模型相匹配,全功能GPU依靠其較強的通用性、完備的開發者生態可適應快速迭代的AI訓練及低成本的AI推理。從芯片形態上看,為追求更低功耗及更極致的性能,突出計算功能的GPGPU也開始出現;而保留圖形渲染能力的全功能GPU,我們認為,仍是滿足未來AI大模型、多模態輸出需求的一站式解決方案。
定製化ASIC或將通過推出適用於大模型的專用產品而獲得市場的一席之地。相較於通用性較強的GPU,我們認為定製化ASIC芯片有望通過將AI算法“硬件化”以及採取更靈活的芯片架構設計(如在芯片內部署更多計算單元來降低SRAM對面積佔用)來實現更低成本、更低功耗下的AI算力提升。我們認為,儘管ASIC芯片在應用生態完備性及產品生命週期連續性方面可能與GPU存在較大差距,但在部分AI算法相對固化的場景下(特別是在推理側),或將通過性價比及功耗優勢獲得一席之地。
大模型驅動下,雲端AI算力芯片增量市場規模可觀:以英偉達A100GPU等效算力為基準,我們對雲端AI算力市場的測算結果如下(2023-25年合計實現的增量):訓練型AI加速芯片需求增量為60萬張,對應市場規模為72億美元;推理型AI加速芯片需求增量為140萬張,對應市場規模為168億美元。長期來看,考慮到AI計算的複雜化和AI各類應用活躍用户數的快速提升,我們認為訓練、推理型AI算力芯片的市場規模有望保持高增長。
風險
AI算法技術及應用落地進展不及預期;算力芯片市場測算假設發生變化。
正文
AI加速芯片存在不同的架構形態
我們在此前發佈的報吿《AI浪潮之巔系列:服務器,算力發動機》中對服務器上游各個產業鏈環節進行了拆解及價值量測算,其中指出,AI算力芯片是受益最大的環節,同時也是提供算力的底層基礎。在本篇報吿中,我們將更為系統地介紹不同類別的算力芯片的架構特點及差異,以及行業未來的發展方向。
按照芯片的設計理念及用途,AI算力芯片可分為通用芯片和專用芯片,二者各有特點。通用芯片為解決通用任務而設計,主要包括CPU、GPU(含GPGPU)和FPGA;專用芯片(ASIC)為執行特定運算而設計,具備算法固化特性,主要包括TPU(Tensor Processing Unit,張量處理器)、NPU(Neural Network Processing Unit,神經網絡處理器)等。在通用算力芯片當中,CPU內核數量有限,採用串行方式處理指令,適合於順序執行的任務;GPU採用眾核結構,最初開發用於圖形處理,而後憑藉其強大的並行計算能力適用於AI通用計算(GPGPU);FPGA是具備可編程硬件結構的集成電路,其可編程性和靈活性可快速適應AI領域的算法變化。與專用芯片相比,通用芯片主要優勢在於靈活性及生態系統的完善性,可適應高速迭代的算法任務,同時GPU保留的渲染能力可適應大模型的多模態發展,而其主要劣勢則在於較高的功耗水平和較低的算力利用率。專用芯片的優勢則在於通過算法固化實現了更高的利用率和能耗比,以及更低的器件成本,同時ASIC更適合大規模矩陣運算;其主要劣勢是前期投入成本高、研發時間長,且只針對某個特殊場景,靈活性不及通用芯片。
圖表1:不同架構的AI加速芯片對比

資料來源:各公司官網,中金公司研究部
GPU:兼具通用性與高性能,是當下AI算力芯片的主流形態
GPU作為圖像處理器,在設計之初並非針對深度學習,而是專門用在個人電腦、工作站、遊戲機和一些移動設備(如平板電腦、智能手機等)上圖像運算和圖形加速的芯片。由於其強大的並行計算能力和高效的浮點運算能力,GPU逐漸成為深度學習和人工智能領域的首選計算硬件平台之一。同時,隨着NVIDIA等GPU廠商推出針對深度學習的技術和解決方案,GPU在深度學習領域的應用越來越廣泛。
豐富的運算單元助力AI加速
GPU最初目的是為了實現渲染圖形的功能。對於處理圖形數據而言,因為圖形上的每一個像素都需要被處理,所以數據量將會十分龐大,而在NVIDIA公司在1999年提出GPU概念以前,圖形處理任務都是由CPU(中央處理器)來完成的。CPU在運行過程中遵守馮·諾依曼構架:存儲程序、順序執行,因此在處理大量的數據時,CPU很難達到高效。在這樣的情況下,基於對運算速度的要求,專注於圖像渲染,為優化圖形處理而設計的GPU構架應運而生。
CPU和GPU均由運算單元、控制單元和緩存單元組成,但組成佔比存在差異。GPU誕生之初是為解決圖像渲染問題,因其需要面對的是類型高度統一、相互無依賴的大規模數據,故而在GPU中,有數量眾多的運算單元,但只有簡單的控制和緩存單元,以保證其能夠高效地執行相同類型的操作。而CPU作為中央處理器,需要高效地執行通用任務。其具有更多功能模塊,運算單元較少,但具有強大的邏輯運算能力,同時有足夠的控制單元實現複雜的數據控制和數據轉發,以及足夠的緩存單元去存放已經計算完成的結果或是之後需要用到的數據。
圖表2:CPU和GPU架構對比圖
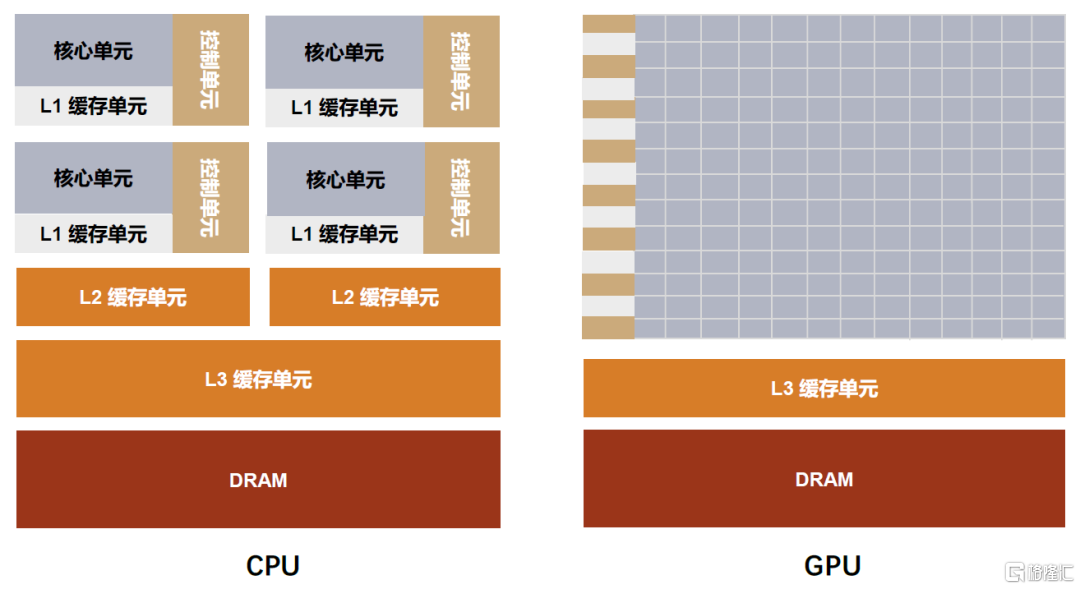
資料來源:NVIDIA官網,中金公司研究部
GPU比CPU更適用於執行高度線程化的並行處理任務,即大規模計算任務。從硬件設計上來講,CPU由專為順序串行處理而優化的幾個核心組成,而GPU則由更小、更高效的核心組成,這些核心專為同時處理多任務而設計。傳統的串行編寫軟件要運行在一個單一的具有單一中央處理器(CPU)的計算機上,同時一個問題分解成一系列離散的指令,指令必須一個接着一個執行。而並行計算可以使用多個處理器運行,且一個問題可以分解成可以同時解決的離散指令,提高了算法的處理速度。
圖表3:串行運算及並行運算示意
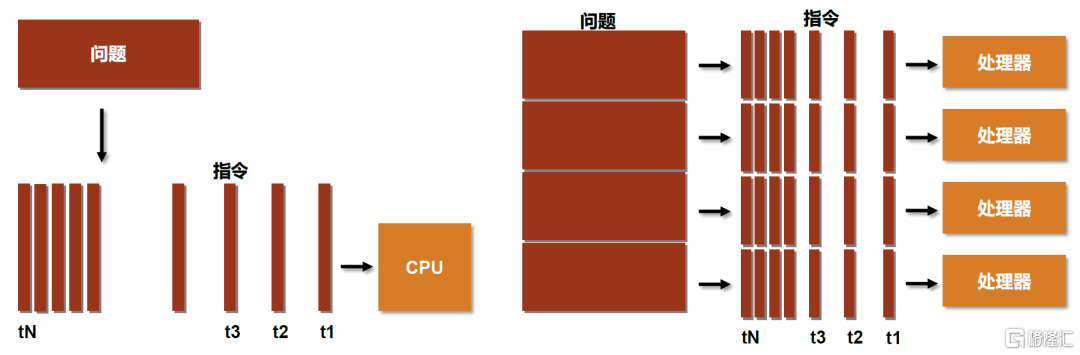
資料來源:CSDN,中金公司研究部
因此,與傳統CPU相比,GPU具有多線程、高核心數、更高的訪存速度和浮點運算能力等優勢。隨着數據量不斷增加和計算需求不斷增強,傳統的CPU難以滿足大量數據計算的要求。GPU的並行計算能力更強,能夠同時處理大量的數據和任務,具有CPU難以具備的優勢。在大數據領域中,GPU主要用於加速計算密集型任務,例如,機器學習、圖像處理、深度學習、模擬計算等。根據NVIDIA的產品線來看,每一代GPU的升級在耗費功率更低、佔用基礎設施更少的情況下能夠支持遠比從前更大的數據量和吞吐量。
圖表4:主流型號NVIDIA GPU性能情況
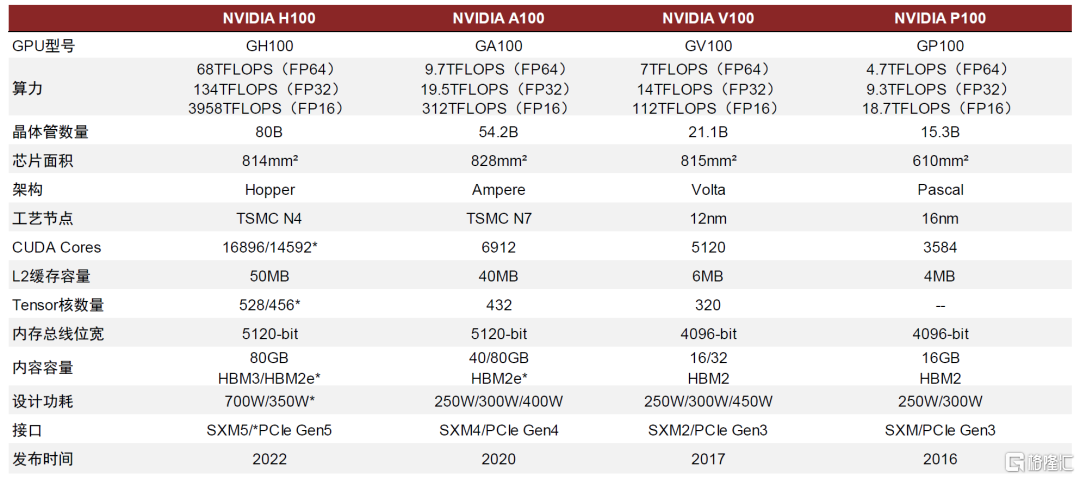
資料來源:NVIDIA官網,中金公司研究部
硬件通用性契合當前AI算法的快速迭代
AI模型的算法快速迭代,對硬件通用性提出要求。深度神經網絡是具備至少一個隱層的神經網絡,是深度學習的基礎,算子是組成深度學習算法的計算單元,在網絡模型中對應層中的計算邏輯。AI模型算法的升級演進呈現日新月異的發展態勢,目前已發展為MLP、CNN、RNN、BERT等多種模型百花齊放的局面。多層感知器(MLP,Multilayer Perceptron)是一種前饋人工神經網絡模型,不同層之間採用全連接,但全連接帶來的數量級的權值參數易引發過擬合、局部最優等一系列問題;卷積神經網絡(CNN,Convolutional Neural Networks)是一類包含卷積計算且具有深度結構的前饋神經網絡,通過“卷積核”能夠實現參數個數限制和局部結構挖掘,適用於圖像識別,雖然可以並行訓練,但是內存佔用大;循環神經網絡(RNN,Recurrent Neural Network)是一種具有短期記憶能力的神經網絡,通過增加隱藏層之間節點的連接,可適應對時序數據的處理;長短期記憶(LSTM,Long Short-Term Memory)是RNN的一種,能夠保持前序信息的長期存儲,緩解了傳統RNN模型仍然存在的梯度消失和梯度爆炸問題,適用於語音識別等;Transformer不同於傳統CNN和RNN,整個網絡結構由Attention機制組成,前後沒有“時序”,可實現並行計算,而且由於Transformer的矩陣維度較少,內存佔用較少。BERT預訓練語言模型即使用Transformer模型的encoder層來進行特徵提取。根據Google2021年發佈的論文《Ten Lessons From Three Generations Shaped Google's TPU v4i》,2016-2020年期間,不同的算法模型在Google應用程序工作負載中的比例發生較大變化。最基礎的MLP模型由於存在參數膨脹、梯度消失、無法對時間序列建模等一系列缺陷,其使用的比例由2016年主導的61%逐步下降至2020年的25%;CNN模型在MLP的基礎上憑藉“卷積核”緩解了參數數量膨脹問題,其使用的比例由2016年的5%增長至2020年的18%;RNN則進一步克服了CNN無法對時間序列變化建模的侷限性,其使用的比例實現由0%到29%的快速領先;而誕生於2018年的全新預訓練語言模型BERT由於具備了並行計算的高效性,在短短兩年內實現飛速增長,2020年已佔到Google內部應用的28%。由此可知深度學習模型迭代更新的高速趨勢。總體來看,我們認為AI模型的算法、算子迭代速度較快,新的模型出現對傳統模型可能起到顛覆性的替代效果。
圖表5:Google應用當中深度神經模型算子的迭代變化
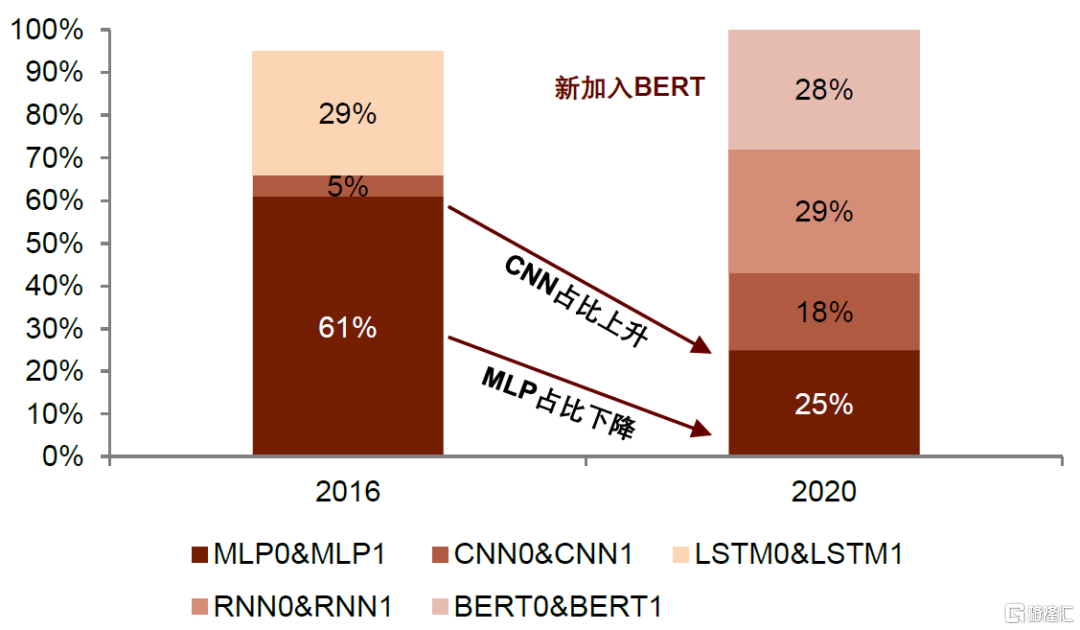
資料來源:Norman P. Jouppi, David Patterson, etc.,Google LLC,《Ten Lessons From Three Generations Shaped Google’s TPU v4i》,2021,中金公司研究部
硬件芯片的設計需要與軟件算法相匹配。軟件算法AI生態需要底層硬件、中間深度學習平台、上層應用軟件之間的整體適配和互相支持,硬件芯片對於計算密集型的深度學習非常重要,在設計AI芯片時,需要緊密結合神經網絡的計算特徵,在成本、硬件效率與未來預期之間進行平衡。例如由於深度神經網絡中矩陣乘法佔據大部分計算量,因此芯片中需要加入高效計算矩陣乘法的硬件單元,如CubeEngine、Tensor Core等,以支撐深度神經網絡結構的實現。而加速器硬件不僅需要進行矩陣計算,還需要支持激活(Activation)、池化(Pooling)、標準化(Normalization)、張量操縱(Tensor Manipulation)等操作,其中一部分操作可能隨着神經網絡的演變而不斷變化,這就對芯片的可編程性提出要求,硬件上的可編程性也可以理解為對未來算法迭代的保險。因此可見,硬件芯片與深度神經網絡的變化緊密相關。
圖表6:神經網絡中的典型操作計算

資料來源:算力基建,中金公司研究部
AI算法迭代與處理器芯片研發存在時間差,通用性更強的GPU處理器芯片可以較快滿足需求。不同於軟件層面的高速迭代升級,硬件層面處理器芯片具備較長的研發週期。對於通用芯片,根據NVIDIA GPU工程部門主管Jonah Alben所述,NVIDIA開發Ampere GPU歷經4年時間。雖然通用GPU芯片研發週期漫長,但由於其具備通用性,並不與特定算法模型綁定,因此無需在算法迭代時重新進行架構設計,適用於算法多元且不斷演進的領域。而對於專用芯片,億歐智庫數據顯示,ASIC芯片的開發週期為1-3年,開發投入費用高達800-2500萬美元以上。由於其按照特定算法和架構進行設計,對算法依賴性強、定製化程度高,因此其算法邏輯一旦設計完成較難進行後續修改,這導致ASIC芯片產品在AI算法高速演進的趨勢下需要保持較高的更新頻率,意味着更高的持續投入成本,而考慮到軟硬件開發週期存在的時間差,已開發完成的ASIC芯片容易面臨被市場淘汰的風險。因此,開發週期較長的計算芯片需要具備足夠的通用性和靈活性,以適應高速迭代更新的AI計算任務,從而利於實現投資保護。
圖表7:ASIC芯片開發成本

資料來源:Tsai, Yu-Wen & Wu, Kun-Chen & Tung, Hui-Hsiang & Lin, Rung-Bin,《Using structured ASIC to improve design productivity》,2009,中金公司研究部
圖表8:ASIC設計流程

資料來源:RF Wireless World, 中金公司研究部
具有較強的技術壁壘,市場集中度高
全球GPU市場競爭格局較為集中,當前NVIDIA處於市場領導地位,根據Verified Market Research數據,2022年在全球獨立GPU市場當中佔比約80%。雲計算與人工智能是NVIDIA數據中心業務的重要下游需求,過去幾年中NVIDIA的GPU芯片伴隨雲廠商與AI行業不斷髮展,實現了硬件與應用的緊密結合,藉助DSA、NVlink等架構創新和優化,實現持續性能領先。2019-2022年全球雲廠商資本開支增長與NVIDIA數據中心業務收入呈現明顯正相關,雲計算與人工智能構成GPU芯片業績增長的主要動能。
圖表9:NVIDIA數據中心板塊收入與雲廠商資本開支趨勢
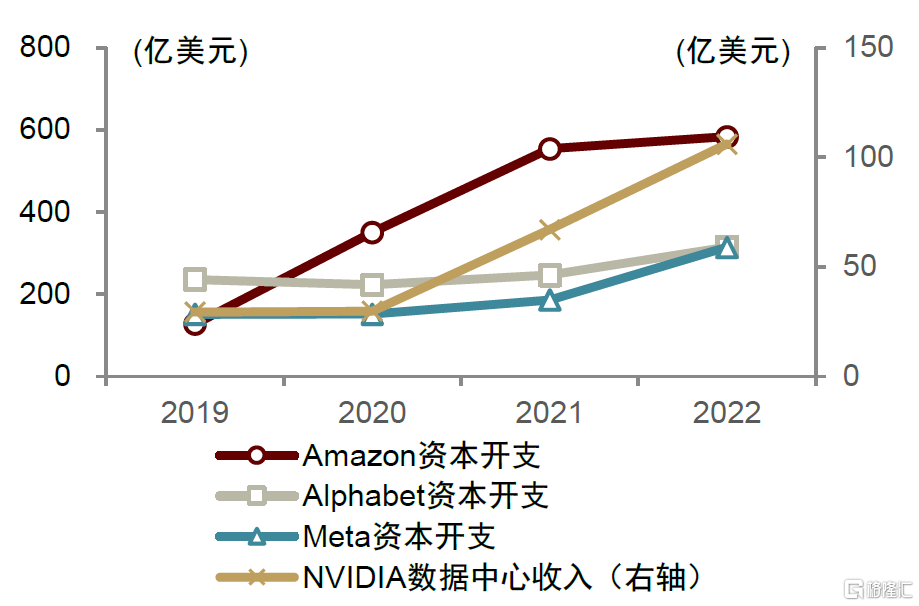
資料來源:Jon Peddie Research,中金公司研究部
圖表10:全球PC端獨立顯卡市場份額
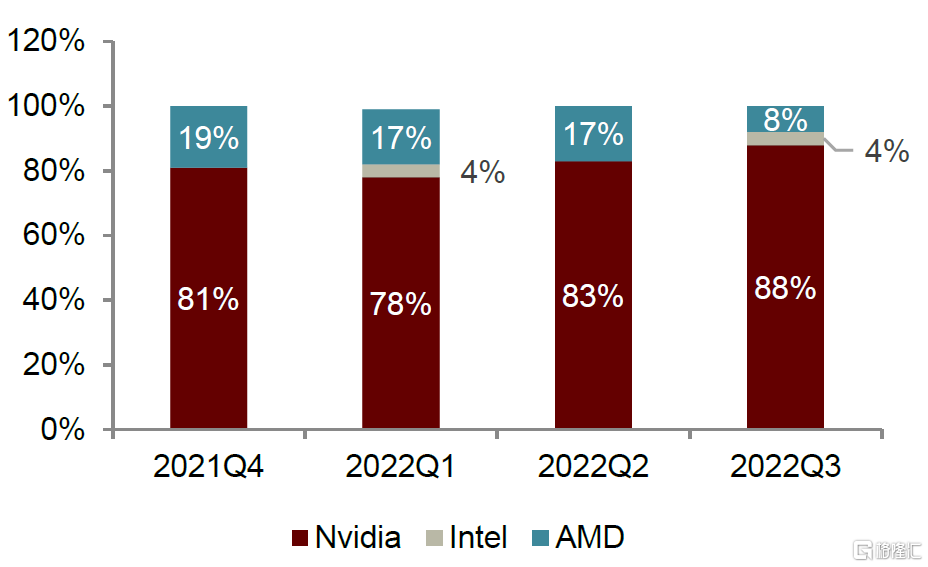
資料來源:Jon Peddie Research,中金公司研究部
圖表11:NVIDIA收入拆分(Q4 FY23)

資料來源:NVIDIA官網,中金公司研究部
我們認為,GPU芯片設計壁壘較高,是一項非常複雜和密集的系統工程,需要涉及硬件和軟件的各個方面。
硬件架構複雜,涉及功能眾多
GPU需要包含大量的圖形顯示功能模塊,並且需要支持大規模的矩陣運算。此外,GPU還需要支持底層精密複雜的硬件結構,以支持高級圖形處理步驟,如光柵化、頂點處理和紋理貼圖等。最新的GPU架構還包含了各種新技術,如全新的RT Core和Tensor Core,以支持可加速光線追蹤和麪向AI推理的功能。
多個GPU的硬件參數值得關注。包括核心數量、浮點計算能力、顯存位寬、顯存帶寬、核心頻率、顯存容量、性能功耗比、內存接口等。其中浮點計算能力越高,説明GPU的計算速度越高,處理能力更強;顯存位寬越大,説明瞬間可以傳輸的數據量越大;核心頻率越高,計算速度也越高;顯存帶寬越高,GPU內存和GPU核心之間的數據傳輸速度越快;而顯存容量的大小直接影響了GPU處理大規模數據的能力。同時部分評估指標之間存在着相互影響,較高的核心頻率可能會提高GPU的計算速度,但同時也會增加功耗和發熱等問題。同時,較高的顯存帶寬通常會提高GPU的圖像處理速度,但同時也需要更高的顯存容量和更高的功耗。
圖表12:GPU核心評價指標及其釋義

資料來源:CSDN,知網,中金公司研究部
不同的架構對應不同性能參數。NVIDIA在推出的第一版架構名為Tesla,在這之後NVIDIA又相繼推出了Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere和Hopper架構,不同的架構更新主要體現在SM(流處理器)和TPC(線程處理器)的更新,最終體現在GPU浮點計算能力的提升。通過對比NVIDIA推出的Geforce系列的GPU可以看出,不同型號的GPU在各指標表現存在較大差異。
圖表13:NVIDIA GeForce系列GPU性能對比
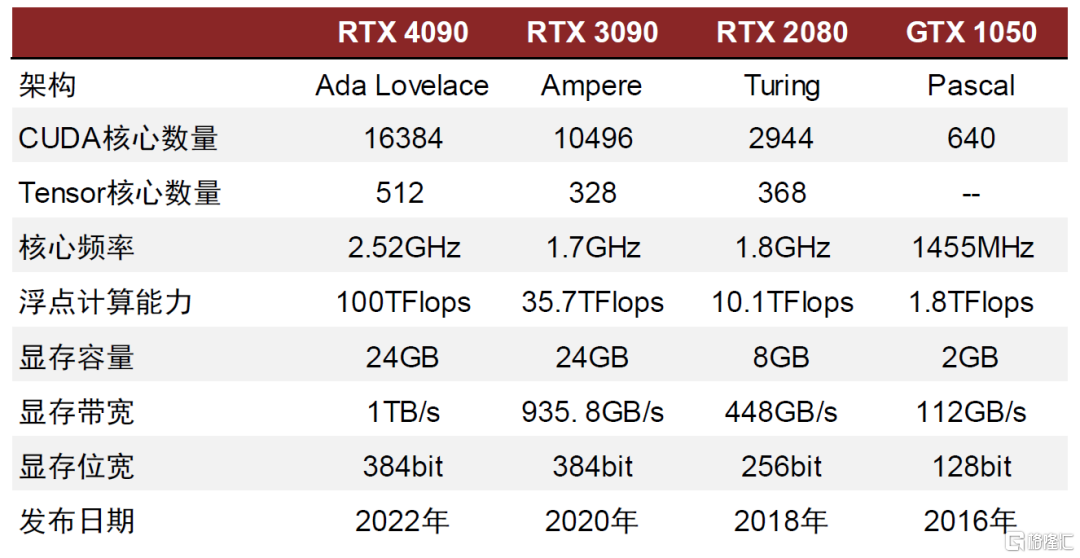
資料來源:NVIDIA官網,中金公司研究部
算法和生態系統構建同樣重要
GPU的算法和生態系統構建也是GPU設計中的重要部分。GPU算法需要與硬件緊密結合,以提高GPU的性能和效率。同時,GPU的軟件生態系統還需要支持各種開發工具和框架,以便開發人員可以更輕鬆地利用GPU進行高性能計算和機器學習。
在軟件生態方面,GPU廠商非常注重構建自己的生態系統。例如,英偉達就推出了CUDA平台,這是一個針對GPU進行並行計算的開發工具和框架。最新的CUDA生態包括編程語言和API、開發庫、分析和調試工具、數據中心工具和集羣管理、GPU加速應用程序和GPU與CUDA架構鏈接六大部分,其形成的龐大生態系統幾乎佔據通用計算GPU領域的全部市場。
CUDA最初是為了加速GPU對圖形處理的支持而設計的,但隨着GPU硬件的不斷進化和發展,CUDA已經成為了通用的並行計算平台,可以支持各種計算密集型應用的加速,如科學計算、機器學習和人工智能等。CUDA提供了一個強大的編程模型,使得程序員可以使用C或C++語言在GPU上編寫高效的並行計算代碼,從而大大提高開發效率。除了可以提高開發效率,還可以充分發揮GPU的性能和能力。此外,英偉達還與行業夥伴建立了商業合作關係,並形成了開發人員社區生態,幫助推動GPU技術的發展和普及。
圖表14:NVIDIA CUDA生態系統組件
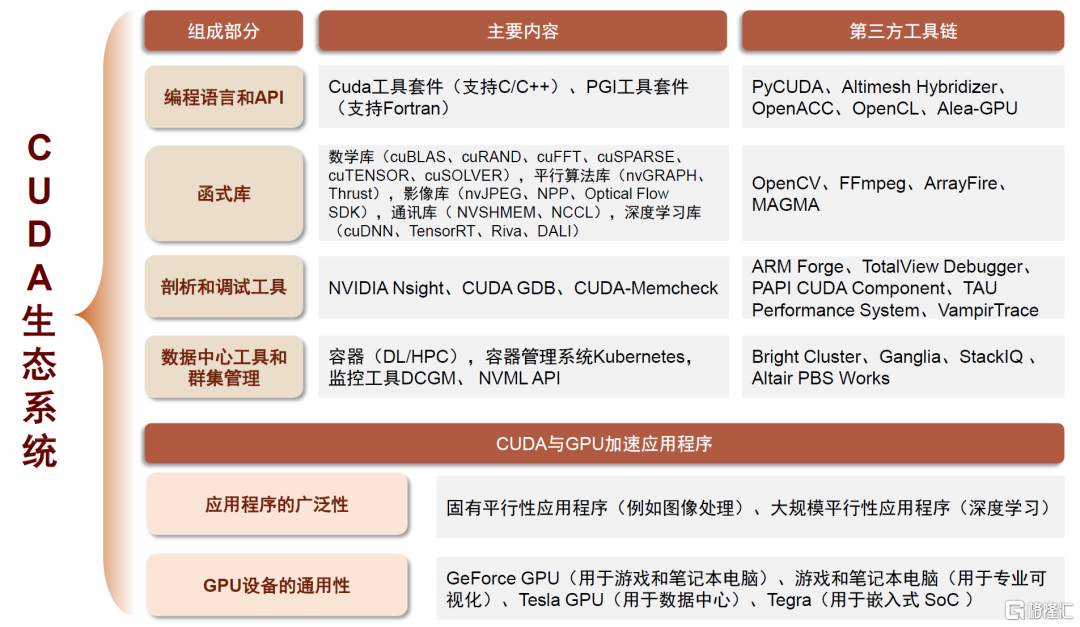
資料來源:NVIDIA官網,中金公司研究部
AI應用拉動GPU市場高速成長,技術參數不斷升級
全球GPU市場穩步發展,下游增長或呈現差異化。根據IC Insights的數據顯示,2022年全球GPU市場規模為400億美元,行業將保持高速增長。GPU下游應用市場廣闊,其中游戲、服務器和汽車領域需求旺盛。由於GPU在圖形渲染和高速處理大規模重複數據方面的優越性,GPU可以應用於遊戲、消費電子、AI服務器、自動駕駛、邊緣計算、智慧安防、加密貨幣、智能醫療等領域。根據NVIDIA財報顯示,在NVIDIA的主營業務中,遊戲、數據中心、專業視覺和汽車這四個領域是目前佔據份額最大的主流應用領域,並且汽車和數據中心的需求在穩定上升。
圖表15:2019-2022全球GPU市場規模
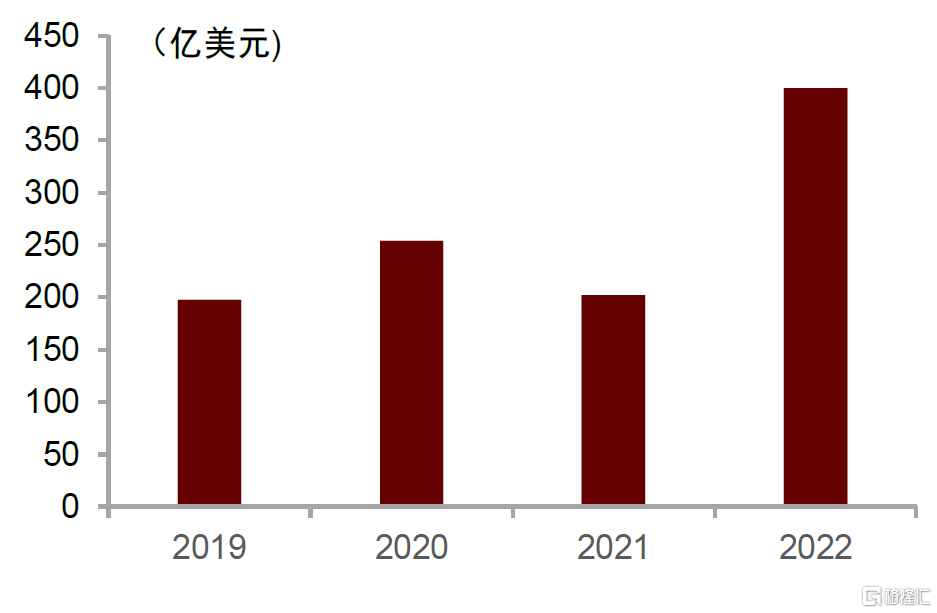
資料來源:IC Insights,Statista,中金公司研究部
圖表16:2015-2022年NVIDIA營業收入構成
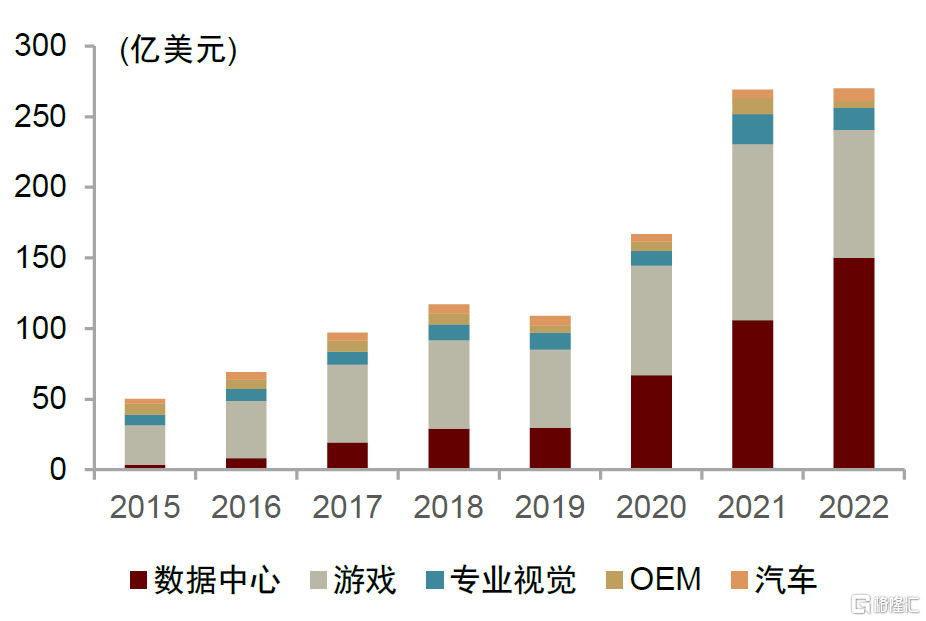
資料來源:Jon Peddie Research,中金公司研究部
目前AI計算主要是以深度學習為代表的神經網絡算法,AI技術發展對於算力提出更高的要求。在上文中我們已經指出,當前深度學習算法在圖像識別、語音識別、自然語言處理等領域都有非常廣泛的應用,常見的深度學習網絡包括CNN,RNN以及Transformer等,他們本質上都是大量矩陣或向量的乘法、加法的組合。同時,神經網絡是一種典型的並行結構,每個節點的計算簡單且獨立,但是數據龐大,通常深度學習的模型需要幾百億甚至幾萬億的矩陣運算。隨着AI技術的不斷髮展,算力需求在不斷提高。根據OpenAI統計數據顯示,從2012年的AlexNet到2017年的AlphaGo Zero的算力實現了30萬倍的提升。
圖表17:1960-2020訓練AI系統所需算力變化
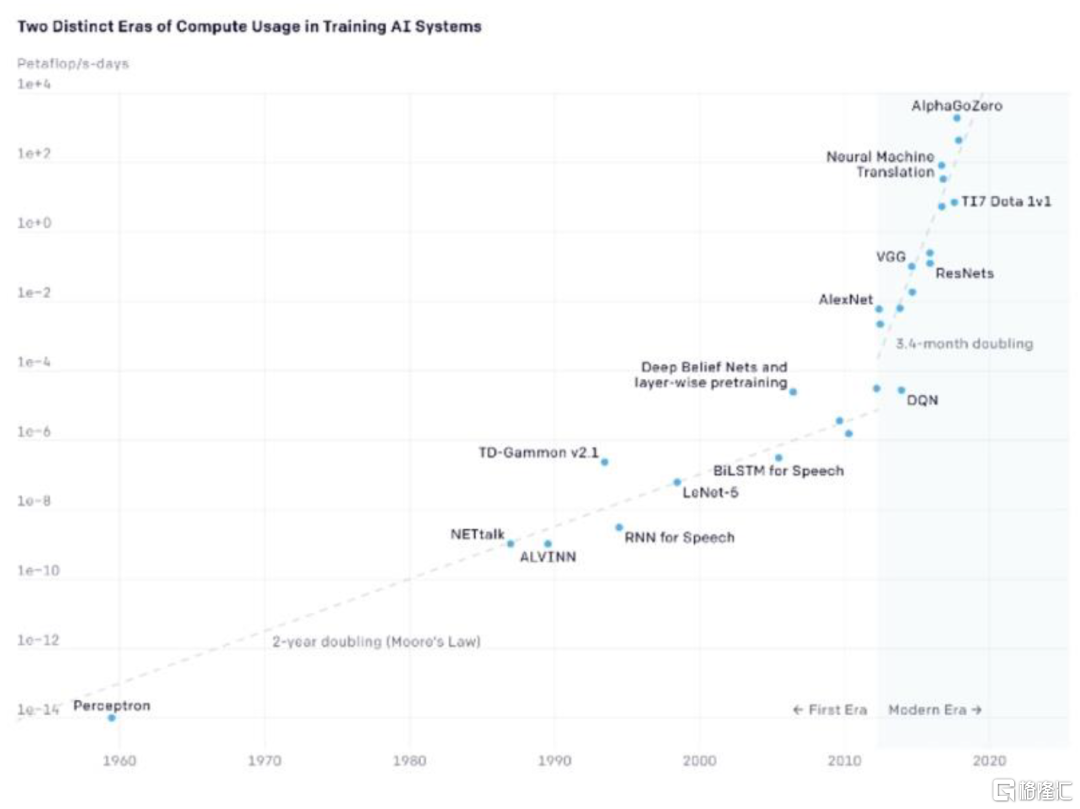
資料來源:OpenAI,中金公司研究部
單GPU架構演進配合AI技術對於深度學習的要求。2010年NVIDIA發佈Fermi架構,之後的架構除了在核心數量和運算能力等參數上有所優化,也發展出了創新性技術以進一步滿足深度學習對算力的需求。在2012年的Kepler架構中應用了GPU Direct技術,可以繞過CPU/System Memory,完成與本機其他GPU或者其他機器GPU的直接數據交換。而2016年推出的Pascal架構,是第一個考慮深度學習的架構,其擁有64個FP32 Cuda Core,同時具備處理FP16的能力,且吞吐率是FP32的兩倍。2017年推出的Volta架構,則完全以深度學習為核心,增加了Tensor Core單元以處理矩陣乘法,使得V100的峯值吞吐率可以達到P100 32位浮點吞吐率的12倍。
圖表18:NVIDIA Fermi架構示意圖

資料來源:NVIDIA官網,中金公司研究部
圖表19:NVIDIA Volta架構示意圖
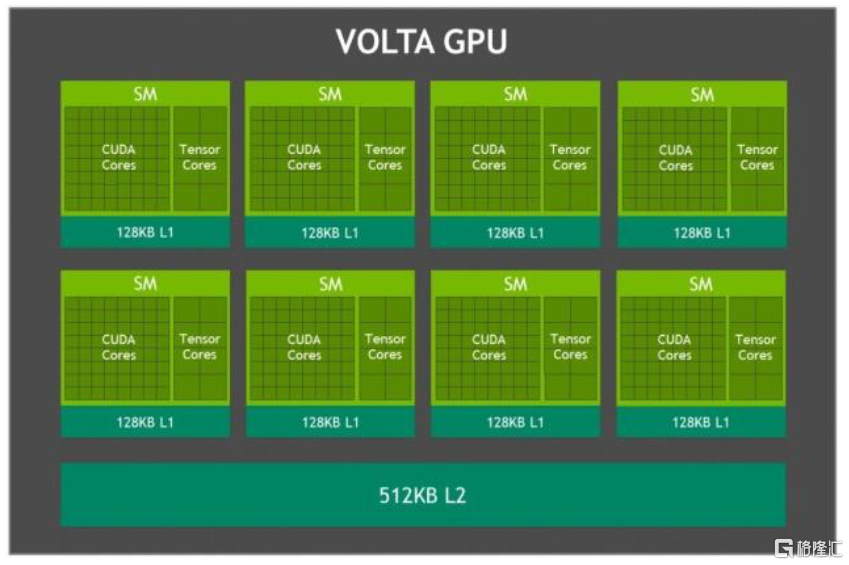
資料來源:NVIDIA官網,中金公司研究部
具體來看,矩陣-矩陣乘法(GEMM)運算是神經網絡訓練和推理的核心,本質是在網絡互聯層中將大矩陣輸入數據和權重相乘。每個Tensor核心都在時鐘週期內執行下圖體現的“D=A*B+C”的運算。其中A,B,C,D都是4x4的矩陣,且A和B是FP16矩陣,C和D可以是FP16或者FP32。通常,在GPU工作中更大的矩陣計算會被拆解為這樣的4x4矩陣乘法。2018年推出的Turing架構中Tensor Core進一步升級,添加了INT8和INT4精度模式,以推斷可以容忍量化的工作負載。而2020年推出的Ampere架構GA10xGPU中的新第三代Tensor Core架構可加速更多數據類型,幷包括新的稀疏性功能,與Turing架構中的Tensor Core相比,矩陣乘法的速度提高了2倍。我們認為,單GPU架構演變對於深度學習提供的支持順應了AI發展對於深度學習的需求,提高了運算速度。
圖表20:Tensor Core矩陣運算示意圖
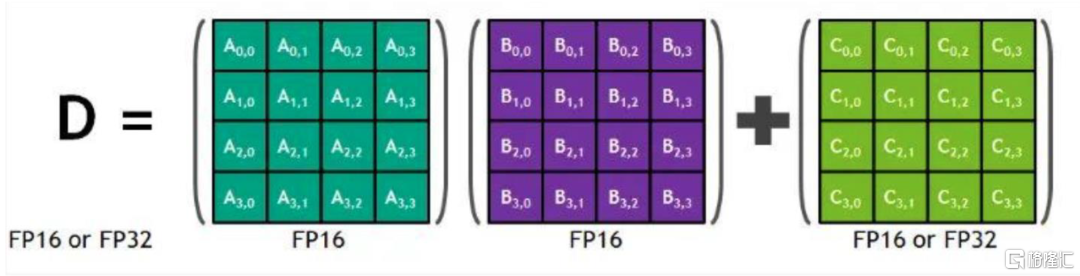
資料來源:CSDN,中金公司研究部
多GPU互聯能力加強,提高並行計算能力。我們看到,隨着單GPU的計算能力越來越難以應對深度學習對算力的需求,NVIDIA開始用多個GPU去解決問題。從單機多GPU到多機多GPU,這當中對GPU互連的帶寬的需求也越來越多。在2014年NVIDIA推出NVLink技術之前,GPU之間以及GPU和CPU之間的數據交換受到PCIe總線影響,速度也成為了瓶頸。為解決PCI Express下的速度制約,NVIDIA推出了NVLink技術,可提供更高帶寬和更多鏈路,並可提升多GPU系統配置的可擴展性,有效解決互連問題。於2016年發佈的P100是搭載NVLink的第一款產品,帶寬達到了160GB/s,大約5倍於PCIe3x16。而到了Volta架構,其擁有的NVLink技術使得每個連接提供雙向各自25GB/s的帶寬,並且一個GPU可以連接6個NVLink。根據NVIDIA數據顯示,NVIDIA NVLink將採用相同配置的服務器性能提高31%,實現深度學習和高性能計算的加速。
圖表21:Pascal架構典型拓撲示意圖
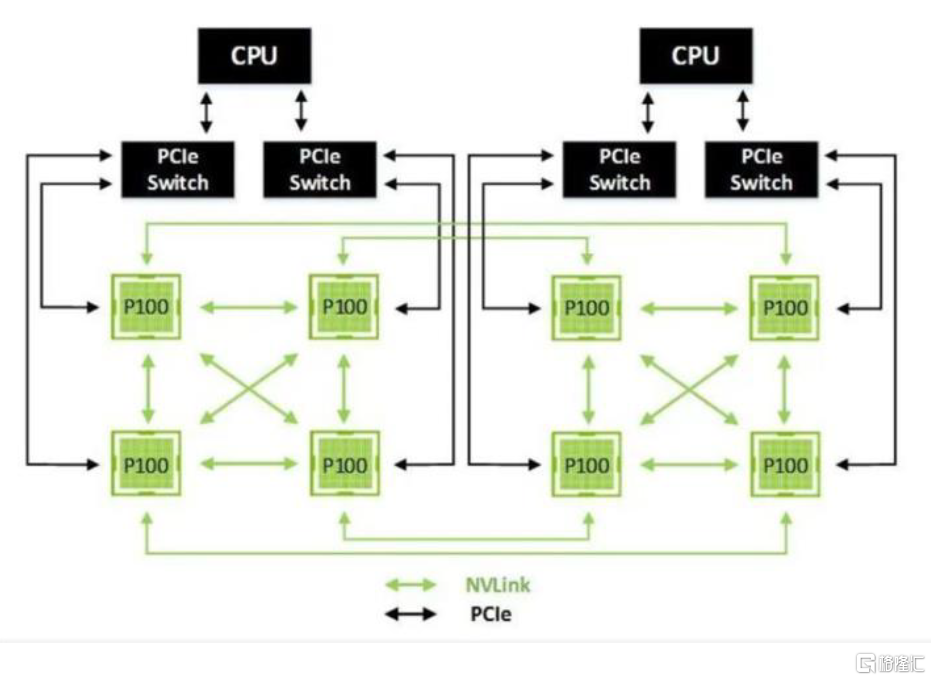
資料來源:CSDN,中金公司研究部
圖表22:Volta架構典型拓撲示意圖
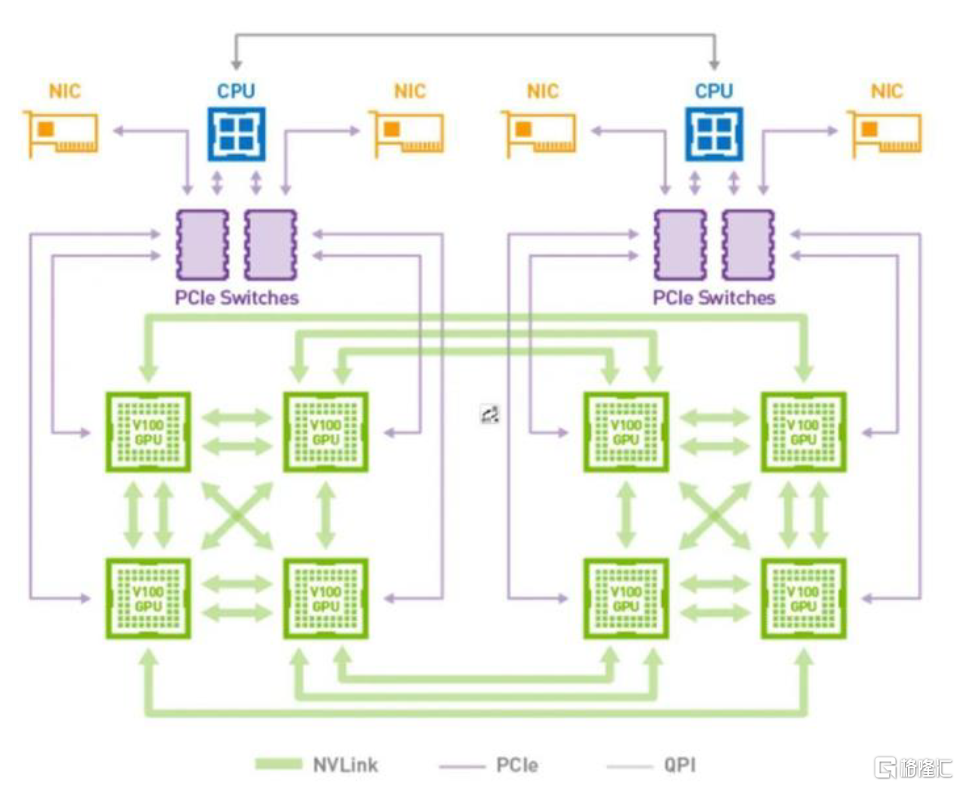
資料來源:CSDN,中金公司研究部
為了使更多的GPU並行,NVIDIA還開發了獨立的交換芯片NV Switch。NVSwitch是安裝在專門的板卡上的一顆獨立芯片,本質上是大量的NVLink物理鏈路及crossbar單元,採用7nm工藝製造,包含約60億個晶體管,NVIDIA通過上述代價,實現了較高的吞吐帶寬。
圖表23:NVSwitch
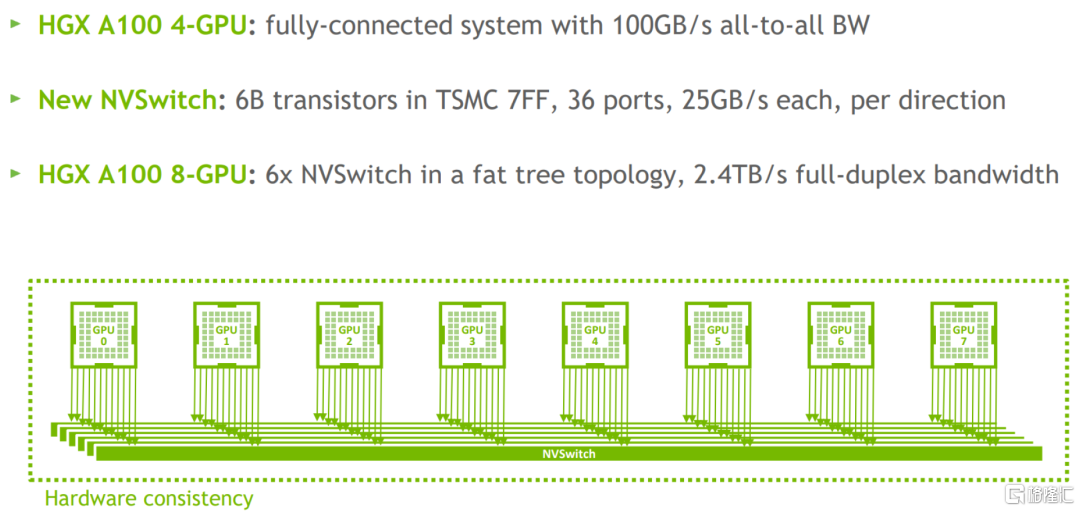
資料來源:《Inside the NVIDIA Ampere Architecture》GTC 2020,中金公司研究部
圖表24:NVSwitch架構圖

資料來源:NVIDIA Developer,中金公司研究部
算力提升同時對GPU顯存要求也日益提高,推動HBM技術發展。隨着顯卡技術的不斷髮展,DDR SDRAM(DDR)逐漸難以滿足需求。1998年,Samsung推出DDR SGRAM(GDDR)。GDDR基於DDR,但針對顯卡應用專門設計了工作頻率、時鐘頻率、電壓,一般來説GDDR相較於DDR時鐘頻率更高,發熱量更小,以達到更好的工作性能。
HBM(high bandwidth memory)指高帶寬內存,本身也是SDRAM芯片,核心思想是通過將多顆相關晶粒堆疊封裝來提高帶寬。顯存的重要性能指標有3個:顯存頻率(800MHz、1,200MHz、1,600MHz、2,200MHz)、顯存位寬(32位、64位、128位、256位、512位、1,024位)、顯存帶寬(顯存帶寬=顯存頻率×顯存額位寬/8bit)。HBM通過TSV堆棧的方式,獲得了更高的I/O數量,顯存位寬能夠達到1,024位,顯存帶寬顯著提升,此外還具有更低功耗、更小外形等優勢。顯存帶寬顯著提升解決了過去AI計算“內存牆”的問題,我們看到在中高端GPU中,HBM的滲透比率日益提高。
圖表25:HBM v.s. GDDR(技術指標對比)(2024E)
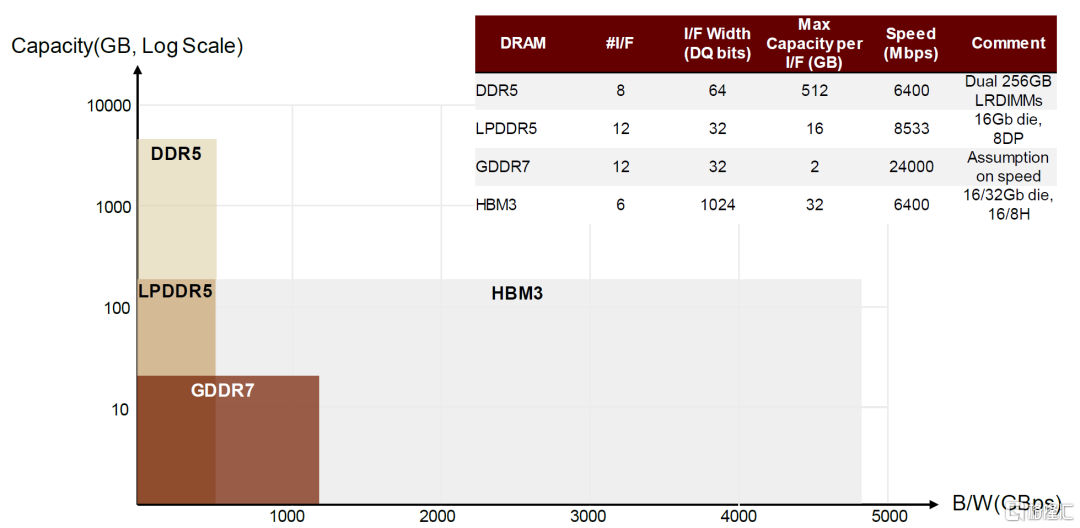
資料來源:SK Hynix官網,中金公司研究部
GPU保留渲染能力,有利於適應未來大模型輸出的多模態發展。伴隨數據規模和模型性能的提升,大模型不僅侷限於自然語言處理(NLP)領域,也在計算機視覺、跨模態等領域展現出較強的拓展性,有望支持多模態信息融合,包括對話問答、寫作、編程、繪畫、視頻創作等各個方面,並不斷擴展應用邊界。例如,2023年3月6日,谷歌與柏林工業大學的AI研究團隊推出一種多模態具身視覺語言模型PaLM-E(Pathways Language Model with Embodied),該模型將PaLM語言模型與ViT視覺Transformer模型相結合,最終參數量高達5620億,能夠實現將視覺和語言集成於機器人控制當中,除語言、文字以外,其應用涉及的多模態信息包括狀態、圖片、3D場景等。2023年3月15日,OpenAI發佈多模態大模型GPT-4,其重大突破在於能夠接受圖像輸入,再輸出正確的文本回復,成為擴展深度學習的最新里程碑。多模態、跨模態領域發展趨勢下,圖像、視頻等成為重要的輸出方式,將存在對圖形渲染的廣泛需求。GPU相比CPU能夠取得相同工作量下的更快渲染速度,大幅加快製作週期,也減少了再次適配硬件的人工成本,我們認為GPU擁有的圖形渲染能力有望在未來AIGC的多模態發展趨勢下發揮優勢。
圖表26:PaLM-E多模態語言模型(谷歌)

資料來源:Techtalks,中金公司研究部
ASIC:生態尚待發展,但可能是未來低成本的算力解決方案
架構靈活,降低內存成本,適應大模型算法需求
馮·諾依曼瓶頸帶來內存成本壓力。在馮·諾伊曼結構計算機中,微處理器的運算速度要比內存訪問速度高出數個數量級,因此內存預取是一個關鍵的瓶頸問題,也被稱為的“內存牆”(Memory Wall)。我們認為,計算機中大量的計算週期是在等待數據加載到內存中。為解決內存牆的問題,微處理器使用了層次結構的內存,即在結構上採用多級緩存設計,讓規模更小但是訪問速度更快的緩存更接近於處理器,但這同時也會帶來內存成本壓力。以常用於高速緩存的SRAM為例,其價格高昂,根據Next Platform估算,SRAM成本可佔芯片成本的30%-40%。此外,根據TSMC在IEDM 2022上的論文[1],TSMC 3nm工藝下SRAM的密度,相比5nm而言,幾乎沒有提升,可見其成本降低愈發困難。
圖表27:內存金字塔示意
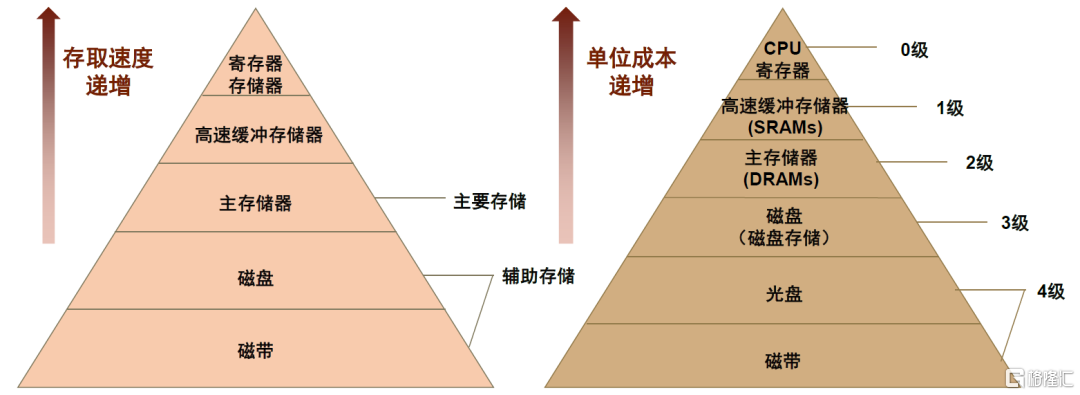
資料來源:Byjus,中金公司研究部
圖表28:SRAM面積降低速度放緩,因此價格/成本降低困難

資料來源:WikiChip,中金公司研究部
ASIC的靈活架構,可以減少內存訪問,從而降低內存成本。我們認為,每家ASIC設計廠商所採用的ASIC架構各異,以Google TPU舉例來看,TPU的MMU有着與傳統CPU、GPU截然不同的架構,即脈動陣列(Systolic Array)。在脈動陣列中,數據一波波流過芯片,與心臟跳動供血的方式類似。如下圖所示,CPU和GPU在每次運算中都需要從多個寄存器(Register)中進行存取,而TPU的脈動陣列將多個運算邏輯單元(ALU)串聯在一起,複用從一個寄存器中讀取的結果。每個ALU單元結構簡單,一般只包含乘法器、加法器以及寄存器三部分。當每個乘法被執行後,其結果將被傳遞到下一個乘法器,同時執行加法,因此結果將是所有數據和參數乘積的和。在大量計算和數據傳遞的整個過程中,MMU不需要執行任何的內存訪問,有效增加數據複用、降低內存帶寬壓力。
圖表29:TPU脈動陣列與CPU、GPU對比
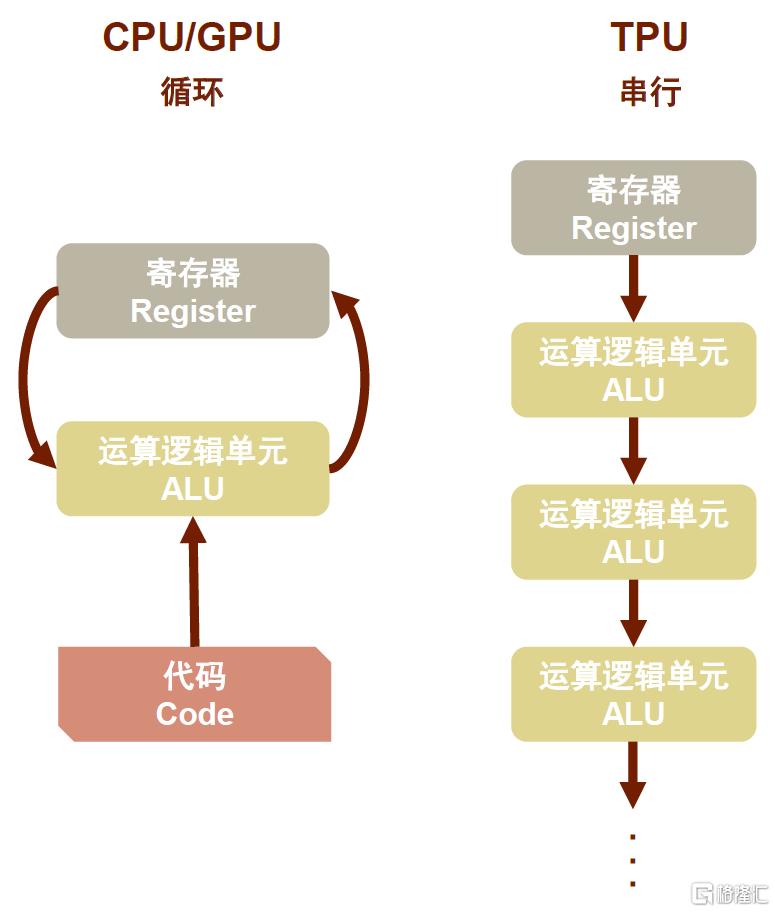
資料來源:Google Cloud,中金公司研究部
未來大模型趨勢需要大規模矩陣運算。根據機器學習的計算原理,神經網絡在數據和參數之間需要執行大量的乘法和加法,這些乘法與加法組合又稱為矩陣運算。對於大模型而言,隨着訓練神經網絡的參數量不斷增加,矩陣運算的量級也逐步攀升。2021年西班牙瓦倫西亞理工大學研究表明,CNN神經網絡中參數量和計算量的相關係數為0.772,Transformer相關係數為0.994,説明在這兩種主流架構中,參數量和計算量都是同步擴展的。
ASIC的大核結構適合大規模矩陣運算。以TPU為例,不同於CPU的多核和GPU的眾核,它僅包含1-2顆大核。矩陣乘法單位(MMU,Matrix Multiply Unit)是TPU的大核心,佔芯片面積的25%。它由256 x 256個乘加組件(MACs,Multiply–Accumulate Operations)組成,每個MAC可以執行8bits整型乘加操作,在單個時鐘週期內能夠處理數十萬次矩陣(Matrix)運算。由此可見,大核結構的ASIC將更適合做大規模的矩陣運算,從而更好滿足未來Transformer網絡大模型的運算需求。
圖表30:算力需求和參數量的關係(線性擬合)

資料來源:Desislavov Radosvet,Plumed Fernando & Hernandez-Orallo Jose,《Compute and Energy Consumption Trends in Deep Learning Inference》,2021,中金公司研究部
圖表31:TPUv1內部結構框圖
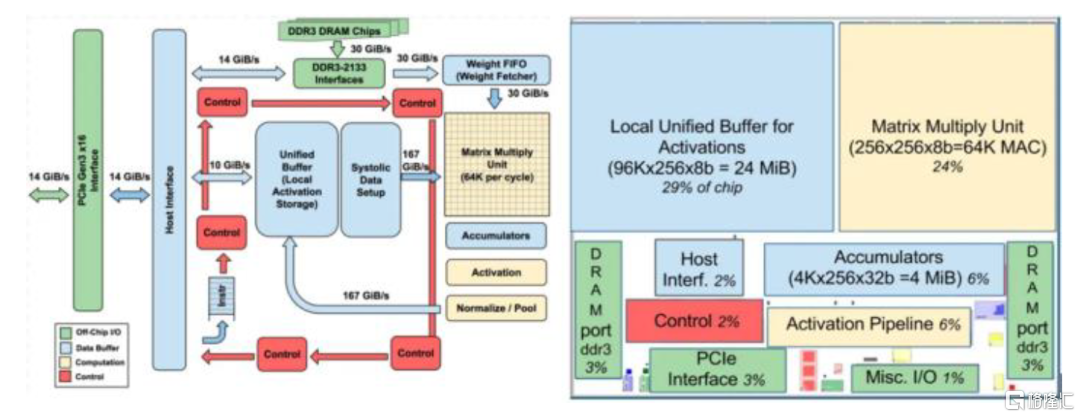
資料來源:Norman P. Jouppi & Rick Boyle,ACMSIGARCH Computer Architecture News,《In-Datacenter Performance Analysis of a Tensor Processing Unit》,2017,中金公司研究部
軟硬件緊密協同,算力成本大幅優化,ASIC存在發展機會
專用芯片軟硬件協同緊密,算力利用率高於通用芯片,有助於節省成本。芯片利用率是芯片實際算力與芯片峯值算力的比值,它衡量了芯片在實際應用過程中的性能表現,彌補了理論上限的不全面之處。ASIC(Application Specific Integrated Circuit)是專用集成電路,針對用户對特定電子系統的需求,從根級設計、製造的專用應用程序芯片,其計算能力和效率根據算法需要進行定製,是固定算法最優化設計的產物。經過算法固化後,專用芯片與軟件適配性較高,從而能夠調動更多硬件資源,提高芯片利用率。而通用芯片由於算法不固定,其硬件往往會產生宂餘,導致芯片利用率較低。
根據國外Toward Data Science論壇文章測算,近1/3用户在實際深度學習訓練中GPU的平均利用率低於15%。2019年哈佛大學研究表明,對比NVIDIA V100 GPU和Google Cloud TPUv2/v3,TPU在CNN框架下的算力利用率是GPU的2.2倍,在RNN框架下的利用率是GPU的3倍,在Transformer框架下則接近5倍。根據NVIDIA和Google Cloud官網,7nm的NVIDIA A30 GPU算力為330TOPS(INT8),面積為826mm²,與之相近算力(275TOPS)的7nm的GoogleTPUv4面積不超過400mm²。我們認為這體現出TPU為代表的ASIC有望通過提高芯片利用率以達到節省芯片製造成本與功耗的作用。
圖表32:深度學習訓練中用户GPU平均利用率
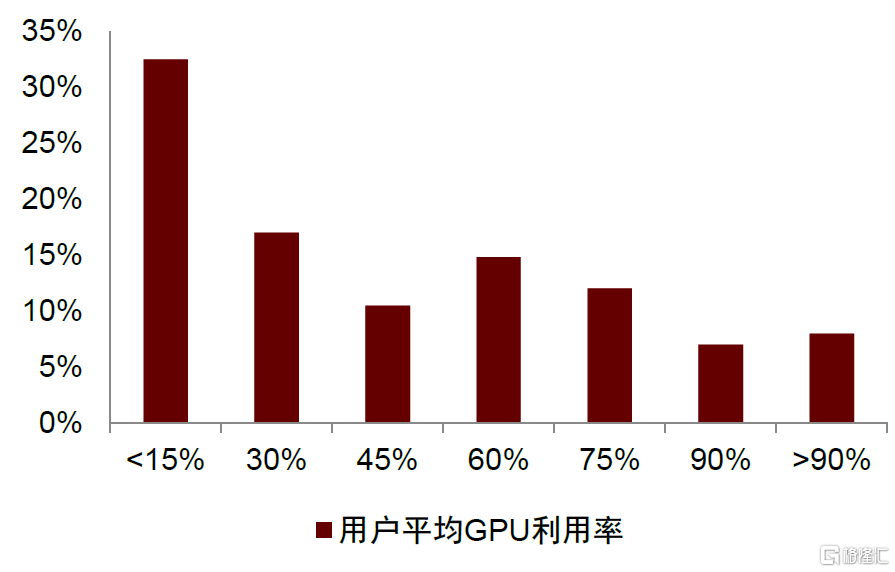
資料來源:Toward Data Science,中金公司研究部
圖表33:TPU和GPU在不同架構中的算力利用率對比

資料來源:Yu Emma Wang, Gu-Yeon Wei, and David Brooks, Harvard University,《Benchmarking TPU, GPU, and CPU Platforms for Deep Learning》,2019,中金公司研究部
專用芯片將AI算法“硬件化”,特定算法下能效比更高。能效比是芯片性能與功耗的比值,能效比越大,完成等量計算消耗的能量越少。專用芯片為特定應用程序設計,其電路高度優化且宂餘少,最大程度提高能效比。以張量處理器(TPU,Tensor Processing Unit)為例,它是一種ASIC芯片方案,專用於神經網絡工作負載,支持其所需的大規模矩陣加乘運算。與圖形處理器(GPU,Graphics Processing Unit)相比,TPU採用低精度(8位)計算,以降低每步操作使用的晶體管數量,從而大幅降低功耗、加快運算速度。同時,TPU使用了脈動陣列的設計,用來優化矩陣乘法與卷積運算,減少I/O操作。TPU還採用了更大的片上內存,以此減少對片外內存的訪問,更大程度地提升性能。在運行AI工作負載上,TPU與同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(perf/W)。此外,在TPU中採用GPU常用的GDDR5存儲器能使性能指標(TPOS)再提高3倍,並將能效比指標(TOPS/W)提高到GPU的70倍,CPU的200倍。再看神經網絡處理器(NPU,Neural Network Processing Unit),其用電路模擬人類的神經元和突觸結構,專用於加速神經網絡的運算。NPU通過數據分區和有效調度,利用數據的重用以及執行分段來提高能效比;同等功耗下,NPU的性能可以達到GPU的118倍。
成本結構中電費佔比大,下游客户偏好高能效比芯片。根據Google TPU團隊傑出工程師David Patterson教授總結,實際生產中不僅需要控制採購成本,還應該節約電力、冷卻、空間等運營成本。其中,採購成本是一次性的,而運營成本將持續支出3-4年,後者可佔總擁有成本的50%。因此,芯片及主板生產商只要考慮產品性能/資本成本的比率,而Google等下游客户要考慮整個硬件生命週期的成本,關注性能/總擁有成本的比率。我們認為未來,隨着算力需求增加,電費成本將持續提升;同等算力下,能效比更高的專用芯片將更受青睞。
圖表34:TPU能效比相對於CPU或者GPU的比值

資料來源:Norman P. Jouppi & Rick Boyle,ACMSIGARCH Computer Architecture News,《In-Datacenter Performance Analysis of a Tensor Processing Unit》,2017,中金公司研究部
圖表35:芯片擁有成本(TCO)結構
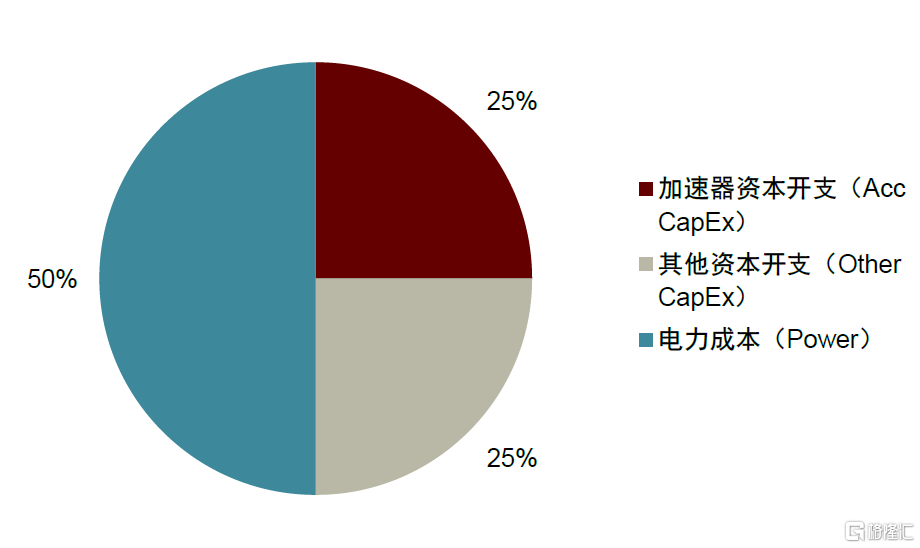
資料來源:Norman P. Jouppi, David Patterson, etc.,Google LLC,《Ten Lessons From Three Generations Shaped Google’s TPU v4i》,2021,中金公司研究部
圖表36:TPU與GPU的對比
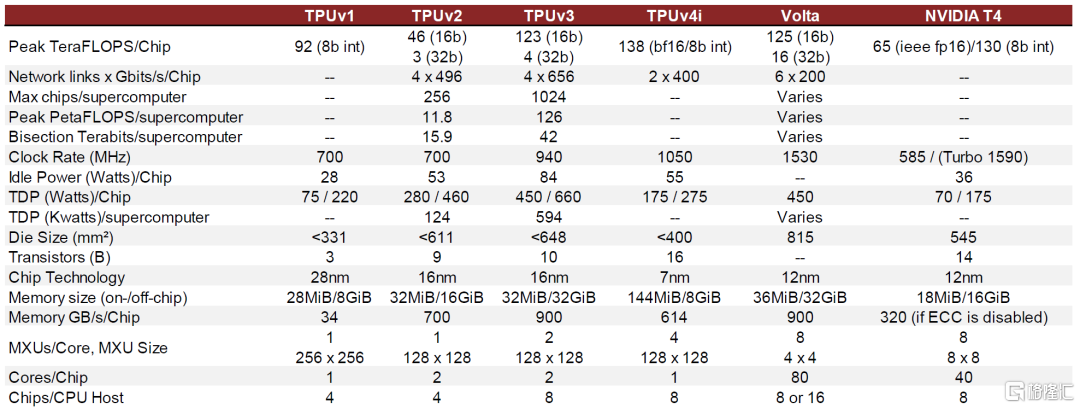
資料來源:機器之心,Norman P. Jouppi, David Patterson, etc.,Google LLC,《Ten Lessons From Three Generations Shaped Google’s TPU v4i》,2021,中金公司研究部
若Transformer模型結構持續成為主流,ASIC市場迎來發展機會。最近隨着ChatGPT、GPT-4以及Bard等大模型相繼推出,大模型成為市場關注的熱點。以語言類模型為例,大模型包括編碼器-解碼器模型框架(Encoder-Decoder)與編碼器(Encoder)模型。其中Encoder-Decoder於2014年提出,當時為了解決機器翻譯中的序列建模問題(Seq2Seq)而構建,隨後演變成機器學習中的常見框架,如無監督算法的auto-encoding、image caption和神經網絡機器翻譯NMT模型都利用了編碼-解碼框架。Encoder-Decoder結構的核心思路是將現實問題轉化為數學問題,通過求解數學問題,解決現實問題。其中,編碼器(Encoder)模型會先對輸入的序列(文字、圖片、音視頻等)進行處理,完成特徵提取,然後將處理後的向量發送給解碼器(Decoder),轉化成用户想要的輸出。Decoder-only則是目前大語言模型最常用的結構,如GPT模型就是decoder-only的代表作。它相比Encoder-Decoder結構減少了編碼的過程,從而節省了一倍的算力,同時避免了encoder雙向注意力造成的低秩問題。目前Encoder-Decoder與Decoder-only成為市場認可度較高的兩類純語言類大模型,國內與國外多家互聯網與雲廠商開始佈局大模型的開發,我們認為如果未來算法的迭代速度相對減慢,上述技術路徑若成為主流,ASIC企業有望通過定製適用於大模型的產品而迎來更大發展機會。
圖表37:GPT-2中的Decoder-only框架示意圖
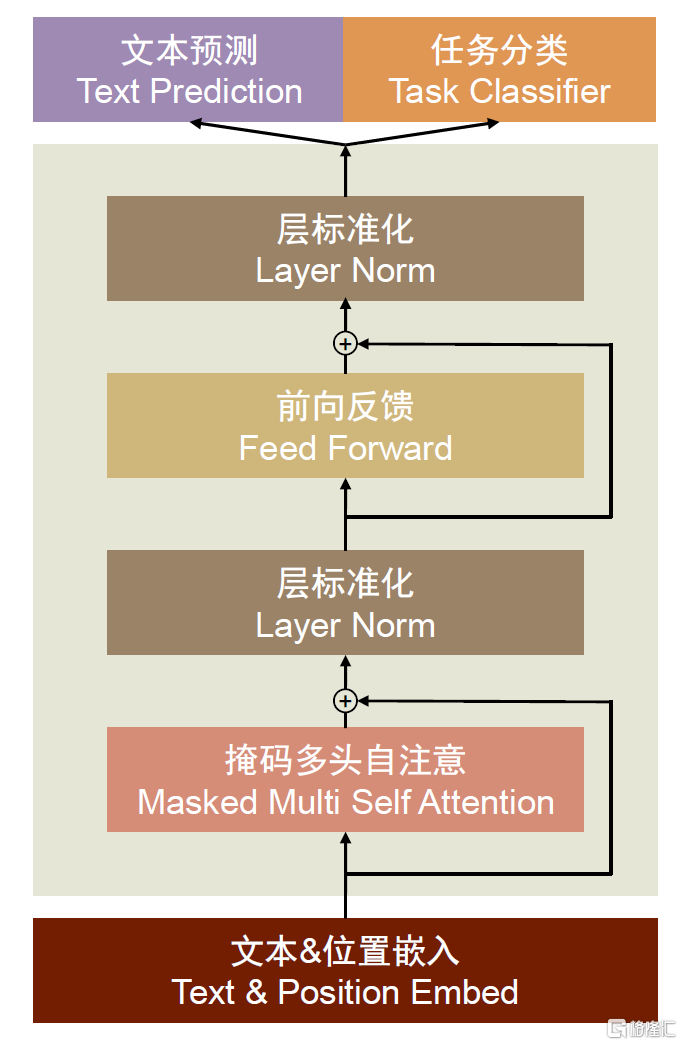
資料來源:Perez Luis,Ottens Lizi & Viswanathan Sudharshan,《Automatic Code Generation using Pre-Trained Language Models》,2021,中金公司研究部
圖表38:Encoder-Decoder框架示意圖

資料來源:CSDN,中金公司研究部
量化分析:AI加速芯片市場有望持續增長
AI計算由雲端和邊緣端兩部分構成。從商用成熟的節奏上,我們認為雲端的模型訓練和推理先行,然後是邊緣端的算力升級;從算力需求規模看,根據華為,邊緣算力將大於中心算力。本篇報吿基於商用節奏和業務兑現確定性的考慮,重點量化雲端算力需求。
在AI雲端場景下,運算對象是大量的類型統一的數據,以並行運算為主,算力衡量指標為每秒浮點運算數FLOPS,典型的硬件芯片代表是GPU(圖形處理器),此外還包括NPU、DPU等;而常見的CPU(中央處理器)由於計算單元只佔小部分,大量空間放置存儲和控制單元,並行計算能力上很受限制,算力衡量指標為每秒鐘可執行操作數OPS。
雲端計算包括訓練和推理兩個過程,首先是對模型的訓練,然後用訓練出的模型進行推理。我們嘗試測算兩個過程的算力資源需求,並提出以下模型和假設條件:
► 訓練:屬於非實時業務,所耗時間可能數天也可能數月,具體取決於模型參數量的多少和算力芯片性能的高低,因此在算力芯片和服務器的投入上,屬於用户對階段性模型訓練需求的一次性成本。在具體測算過程中,我們給出4點假設:①典型AI廠商單一大模型訓練所需的算力投入,分保守、中性和樂觀三種情景;②具有大模型訓練需求的龍頭AI廠商的數量;③假設龍頭廠商佔據模型訓練訓練80%的算力需求;④參考英偉達DGXA100/H100系統配置,假設每台服務器配置8張GPU;
► 推理:屬於實時業務,需要響應客户端觸發的實際需求,算力需求取決於活躍用户數和設計併發數的級別,因此算力芯片和服務器的投入,會隨着模型的商用流行度以及吸引的活躍用户數持續增加。在具體測算過程中,考慮到大模型的應用生態需要一段時間才能成熟,我們區分短期(3年內)和長期(5年左右)兩種情景,並給出3點假設:①活躍用户數及其帶來的最大併發處理次數,分保守、中性和樂觀三種情景;②單Query所需Token數量和單Token所需時間;③容忍延時;④參考英偉達DGXA100/H100系統配置,假設每台服務器配置8張GPU。
我們認為,以上假設條件中的關鍵變量會隨着GPT模型的升級和應用的普及而持續高增長。自2023年2月以來,GPT的熱度持續提高:
► 2023年2月初微軟於將GPT嵌入Bing,根據Data.ai最新數據,嵌入GPT後Bing的app下載量增長近8倍)。
► 3月14日OpenAI發佈ChatGPT升級版,根據官網介紹,該升級版集成的GPT-4是一個大型多模態模型,相較於上一代,其輸入既可以是文字,也可以是圖像。
► 3月16日中國互聯網大廠百度正式發佈文心一言,對標ChatGPT。
► 3月23日OpenAI宣佈為GPT引入插件,首批包括13個第三方插件和2個自有插件,功能覆蓋衣食住行、工作和學習等多領域,至此OpenAI在GPT應用側再下一城。
我們認為以上積極催化並非一時現象,後續隨着大模型、終端應用和產業生態的逐步成熟,一方面,參與大模型訓練和推理的廠商數量將持續增長,從Tier-1雲廠商,到Tier-2雲廠商,再到運營商、金融客户和汽車客户等等;另一方面,模型本身的參數量、用户訪問量也有望顯著提升;如果更進一步地考慮到各廠商之間的算力競爭,以及用户大幅增長之後產生的訪問併發問題,硬件端芯片和服務器的採購需求也會大幅增長。
因此,基於以上算力模型和假設條件,以英偉達A100GPU等效算力為基準,我們對AI雲端算力市場的測算結果如下(2023~2025年合計實現的增量):訓練型AI加速芯片需求增量為60萬張,對應市場規模為72億美元,訓練型服務器需求增量為7.5萬台,對應市場規模為149億美元;推理型AI加速芯片需求增量為140萬張,對應市場規模為168億美元,推理型服務器需求增量為17.5萬台,對應市場規模為348億美元。更長期而言,考慮到AI應用地推廣和活躍用户數的大幅提升,我們測算推理型AI加速芯片和服務器市場規模仍有望保持高增長。
圖表39:AI雲端GPU及其他加速卡芯片、對應服務器增量市場規模測算

注:表格中服務器台數僅基於英偉達A100等效算力測算,不代表中長期實際出貨台數 資料來源:英偉達,中金公司研究部
相關風險
AI算法技術及應用落地進展不及預期。ChatGPT的使用效果超預期引發大模型的浪潮之後,其應用場景和商業化路線仍然較為模糊,雖然目前OpenAI已開始進行ChatGPT商業化路線的探索,包括To C端自有產品的直接變現(例如試點付費訂閲版ChatGPT Plus),以及To B端與第三方產品的集成(例如將ChatGPT嵌入微軟Bing搜索引擎及微軟Microsoft Power App數據分析平台),但是盈利能力仍不確定。我們認為目前各家推出大模型的公司仍在探索商業化路線的早期,其從概念階段發展到真正落地還需要經受時間和市場的檢驗,帶來不確定性。
算力芯片市場測算假設發生變化。我們通過測算,判斷訓練型、推理型AI加速芯片和服務器市場規模有望保持高增長,該測算的核心假設條件是GPT等大模型的部署數有望將持續增長,模型本身的參數量、用户訪問量也將持續增長。如果相關假設發生變化,可能影響算力芯片市場規模的增速。
[1]Did We Just Witness The Death Of SRAM? – WikiChip Fuse
注:本文摘自中金公司2023年4月18日已經發布的《AI浪潮之巔系列:雲端算力芯片,科技石油》
分析員 彭虎 SAC 執證編號:S0080521020001 SFC CE Ref:BRE806
分析員 成喬升 SAC 執證編號:S0080521060004
分析員 唐宗其 SAC 執證編號:S0080521050014 SFC CE Ref:BRQ161
分析員 李學來 SAC 執證編號:S0080521030004 SFC CE Ref:BRH417
聯繫人 於新彥 SAC 執證編號:S0080122080172


More Content