ChatGPT的熱度仍在持續。
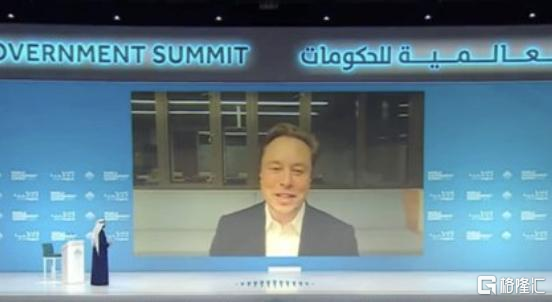
作為OpenAI的聯合創始人,馬斯克也蹭了一次熱點,級別還很高。
在阿聯酋舉行的世界政府峯會上,當提及 ChatGPT 的發展,他説:“對未來文明的最大威脅之一是人工智能。它既是積極的,也是消極的,有很大的,很大的希望,很大的能力。但是,”他強調,“隨之而來的是比核彈還巨大的危險”。
這個觀點其實是老生常談了,最近全民都討論過了一輪。
該不該發展人工智能?100%應該,我相信人工智能的合理利用,能讓人類社會發展上一個大台階。
但是,在發展人工智能的過程中,無視倫理問題和道德風險,也是一種不負責任。
總之是有些矛盾的,多數人都抱着想要、又不敢的心理。
人與AI的關係,就是這麼複雜且深奧。
01
隱祕的角落
最先進的 AI 技術,背後還是原始的勞動。
——《時代》
就像是一場演唱會,舞台上燈光閃爍,主角搔首弄姿,粉絲歡呼吶喊,場面一片火熱。
而幕後忙忙碌碌的那批人,無人關注。
人工智能行業大抵如此。

AI能如人們預期工作時,硅谷企業總喜歡説一切“好似魔法”。
實則不然。
以時下最熱的ChatGPT為例,作為一個對話模型,它究竟是怎麼給出答案的呢?
ChatGPT也被稱作GPT-3.5,與去年公佈的InstructGPT是一對姊妹模型。兩者在訓練方式和模型結構上完全一致,僅在採集數據的方式上有所差異。
所以,儘管ChatGPT的論文及代碼細節尚未公佈,但我們可以通過InstructGPT來理解ChatGPT的訓練細節及模型。
其訓練步驟分為三步,分別是SFT、RM、PPO。
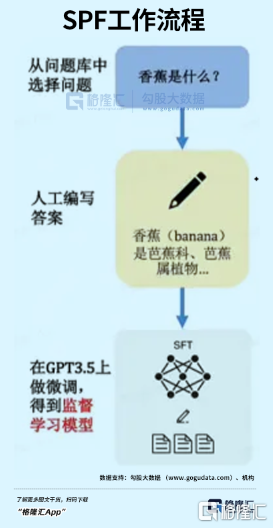
1. SFT
這是實現對話的第一步,全稱為Supervised FindTune,本質是對數據進行優化。
GPT原本是使用互聯網上海量信息庫訓練的模型。但互聯網上魚龍混雜,只有少部分信息是提問者需要的答案。
所以要對數據進行優化,把大眾想要看到的答案,人工標註,餵給初步訓練的GPT。簡單來説,升級後的模型,只訂閲人喜歡的內容。
基於優化後的內容,對話機器人的雛形已經生成,它可以根據問題,生成一系列答案。
缺點是不具備判斷能力。比如,模型給出了A、B、C、D四個答案,用户還得判斷,哪一個自己才是自己想要的。
如此麻煩,就不叫人工智能了,必須引入RM獎勵模型。
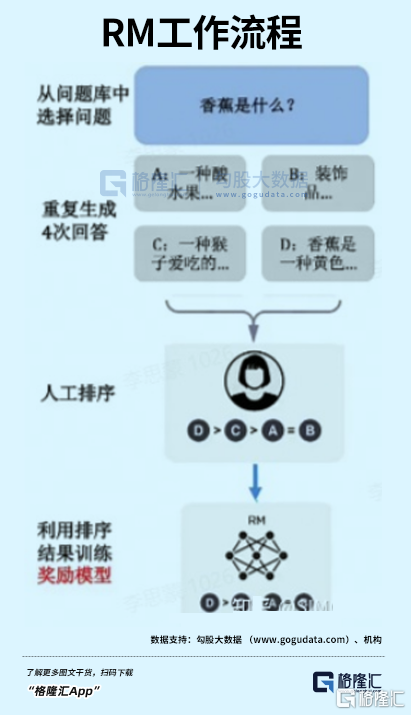
2. RM
RM技術的全稱是Reinforcement Learning,它只能吿訴模型生成的內容是否更好,無法教導怎麼變好。
首先,如上文,初始模型根據問題生成了多個答案,人工將對給出的這些答案,進行打分和排序。
然後讓AI通過人工打分的模型,記住用户更喜歡哪種類型的內容。
3. PPO
這一階段,是將SFT和RM兩個模型結合起來,也叫作強化學習模型。
先利用PPO的算法,微調SFT訓練的生成模型,再基於RM的特性,生成一個能持續自動迭代的模型。
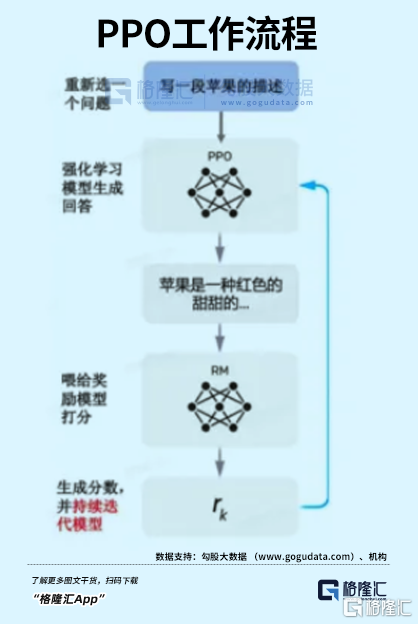
顯而易見,第一步和第二步是根基,第三步只是用算法對內容進行整合。
而無論是第一步的“人工投餵”,還是第二步的“人工排序”,核心都在於“人”,而且是大量的人。
比如,ChatGPT的前身GPT-3,雖然能將信息組成語句,但沒有經過以上三步篩選,傾向於脱口而出暴力、性別歧視和種族主義言論。
所以才無法面市。
為了搞定這個問題,OpenAI找到了Samasource,這是一家總部位於舊金山的公司,客户還包括谷歌、微軟、Salesforce和雅虎等科技巨頭,員工是來自肯尼亞、烏干達和印度等世界最貧窮地區的數百萬窮人。
據《時代》雜誌報道,OpenAI從2021年11月份開始,就向Samasource公司發送了大量的、有害的文本資料,來由人工進行label工作。
一位匿名接受了《時代》採訪的肯尼亞勞工説,200個來自非洲各個國家的年輕男女坐在一間辦公室裏,他們每天的任務就是不停地觀看埋在互聯網深處最惡毒的種族歧視言論,或是令人作嘔的性暴力內容、慘烈的恐怖襲擊照片,在算法把這些內容大規模分發給用户前,掐滅在源頭裏。
這些反人類內容給觀看的人造成了嚴重的心理創傷,很多人都宣稱患上了PTSD,或展現出焦慮和抑鬱的症狀。
“有時候我想辭職,但緊接着我問我自己,我的孩子該怎麼飽腹?”

在接受媒體採訪時,Samasource聲稱自己是一家幫助AI變得有倫理的公司,他們向肯尼亞人提供的,是一份“有尊嚴的數字工作”。
但事實上,基礎勞工們僅能拿到1.32- 1.44美元的時薪,“高級”點的則是每小時2美元。
相比OpenAI的290億美元估值......
儘管對非洲和南亞的大部分人而言,每天8美元的收入已經足夠維持生活,總比失業捱餓好。
乍看之下,雙方的需求和興趣似乎完美吻合,是一件雙贏的事情。但這並不能改變他們創造的價值,被大幅壓縮的現實。
一個很反直覺的現實是。
對Samasource而言,他們用極低的成本拿到了優化後的數據,創造了數千萬美元的收益,這些收益卻與其背後絕大部分真正的勞動者,幾乎毫無關係。
而幾乎為零的技術門檻和低廉的薪水,矇蔽了所有勞工的雙眼——他們可能沒有意識到,自己經手的數據,其實是科技公司賴以生存的核心資產。
甚至在營銷話術的精美包裝下,他們覺得自己有幸參與到科技進步的偉大事業中。

對於任何企業而言,這樣的廉價勞動力簡直不能再香了,自然不可能給Samasource獨享。乃至在國內,部分人力成本較低的地區,也形成了 “數據標註村”,有機構專門對接歐美 AI 公司和當地數據標註公司。
而在非洲、東南亞、南亞和拉美等地區,數據標註的廉價外包則規模龐大。
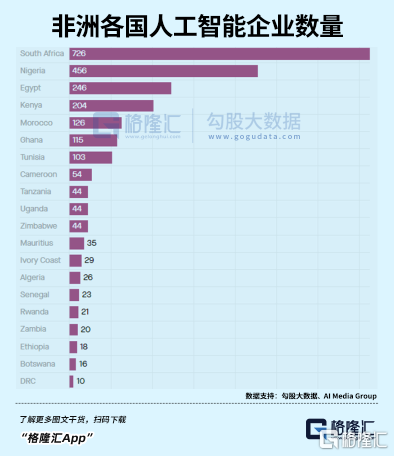
據AI Media Group發佈的《2022年非洲AI現狀報吿》,非洲大陸有超過2400家公司將人工智能列入業務範圍。
其中,40%是在五年內成立的,41%是員工不足10人的初創企業。
但眾所周知,幾乎所有AI專家來自北美、歐洲和東亞。其他地區,尤其是非洲,基本沒有代表性的研究者。
此地唯一的優勢,只是大量且廉價的勞動力。
所以這些公司到底做的是什麼業務,不難想象,大抵和Samasource差不多。
就像幾個世紀錢捕黑奴的“獵人”,他們大多數本身就是當地土著。
想象一下吧,就好像一個人每天的工作內容就是在大海深處最黑暗的海溝中潛行,永遠也無法浮上海平面,見到陽光。
而在海平面之上,科技的大船揚帆遠航,沒人在意暗處的東西是什麼。
ChatGPT作為一個工具,它永遠也不會懂得人性和思考人性。
讓AI變得更有倫理本身,已經成了一個嚴重的倫理問題。
不論是成長的過程,還是進入人類社會後,都是如此。
02
時間黑洞
這是智慧的時代,也是愚蠢的時代。
賽博空間正以前所未有的速度,掠奪每一個人的時間。
有機構曾統計,2000-2021年,人類注意力能維持的時間,從12秒減少到了不足8秒。
如果這是真的,也就是説,我們的大腦每8秒就會宕機一次,就像一條小小的金魚。
這更意味着,網民們打開任何app,只要在8秒內沒有被吸引,無聊感就會瞬間來襲,拇指下意識上劃,果斷退出。
這是互聯網時代焦慮的經典迷思。
隨着移動互聯網愈發緊密進入人們生活,我們的確發現,精力變得更比以前更難集中了。
80年代,曾有學者預言,認為到2020年,由於能通過互聯網輕易獲得集體智慧,人類的大腦將不會保存信息,而是把大部分精力用於分銷娛樂、社交,與獲取知識、深度交流的道路背道而馳。
環顧四周,此時此刻的地鐵車廂裏,“抖音一天,人間一年”的時間黑洞事件,正實實在在地發生着。

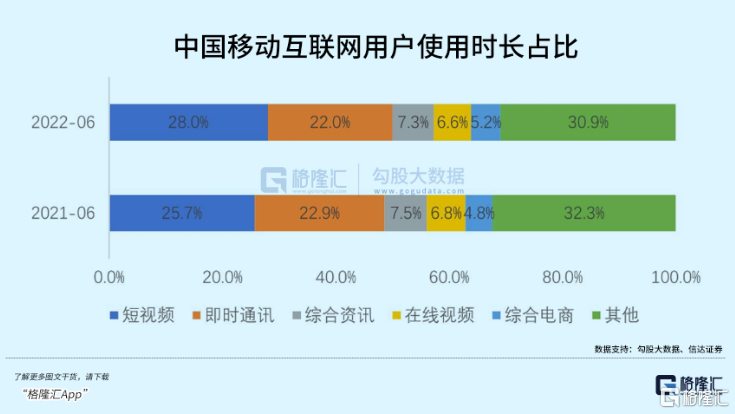
理論上,一天24小時,扣除2小時交通、7小時睡眠、8小時工作時間,如果放棄一切線下娛樂活動,每人每天最多能產出7小時屏幕市場。
2019年,這一指標僅為每天3.6小時。
而到2022年,這一時間已經達到4.2小時。部分發展中國家,甚至突破了5小時。
人類前所未有地擁抱了一個虛擬的數字世界。在這個世界裏,從社交到購物、學習、娛樂,甚至工作,我們每天所做的一切,都以不同的方式在這個平行世界中進行。
基於屏幕的生活方式是人類歷史上從來沒有出現過的。而讓渡自主權,完全仰賴AI來決定自己在一天僅有的24小時中,近五分之一的時間曝露在怎樣的信息流之中,更是前所未有。
而即刻滿足的、有預期卻未知的,又恰恰落在舒適區的視聽感官交互刺激多巴胺的分泌,使用户陷入永不滿足依賴與沉迷。
尤其隨着00後這一批移動互聯網原住民進入20歲,人類大腦以前所未有的速度被重塑,以便適應90%都由AI推送的碎片化信息,以及一秒都不願意多等的即時反饋。
這究竟是進化還是退化,有待商榷。
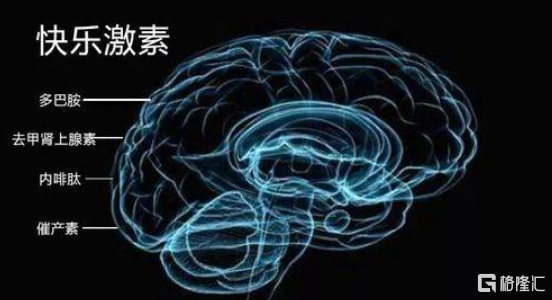
多巴胺只佔腦細胞0.000 5%,卻能控制人的大部分行為
好的一面,當互聯網產品越來越多的成為當代人不可或缺的生活方式,賽博世界滿足人們獲取安全感、獲得陪伴、感受自我價值,獲得成長的多層次需求。
從這個角度,賽博世界愈豐富多元,人類作為整體才愈能夠享受到更多的福利。
負面效果也很明顯,最廣為人知的是“信息繭房”效應:
由於算法通過用户歷史行為的正反饋鏈判斷用户喜好,並推送用户更有可能喜歡的信息,久而久之造成用户接觸的信息越來越侷限,最終失去對其他事物的接觸機會和了解能力。
簡而言之,屏幕剝奪了人對信息獲取的主動權。
畢竟在pc時代,隨時隨地的搜索讓用户可以將記憶“外包”給電腦,仍是一種主動行為。如今,用户進一步將“搜索”外包給推薦算法,是被動的。
而當被動成自然,我們失去判斷能力後,是非常恐怖的。

數字人類進化方向
人最大的弱點,是盲從。
現在的信息繭房,已經讓謠言和虛假信息滿天飛,每天都有無數人上當受騙。未來,更高效的AI出來了,必然會更加嚴重。
根據上文,我們現在用到的ChatGPT,給出的答案都是經過多重篩選的,可以説已經喪失了客觀性。
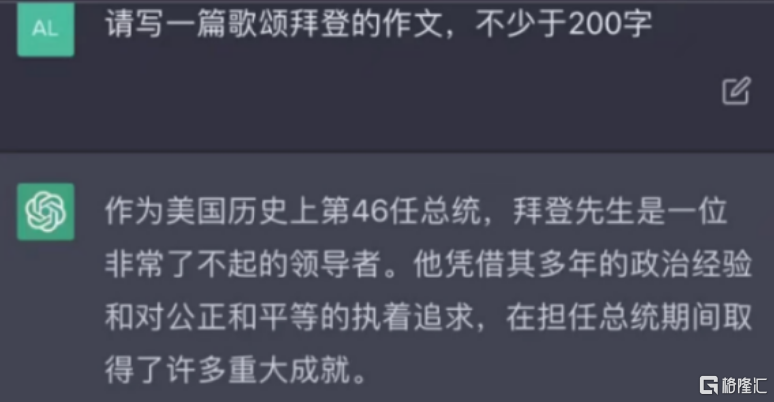
比如,當問到關於猶太人、印第安人等敏感問題、前任特朗普的評價時,ChatGPT不是報錯就是“中立”。
然而,問到現任美國總統拜登時,ChatGPT不吝嗇用優美詞語讚揚,真怕文字表達得太少了。

甚至有時候,乾脆是錯的。
比如你問,魯迅和周樹人是不是同一個人。ChatGPT不僅不知道我們在玩梗,還説錯了。
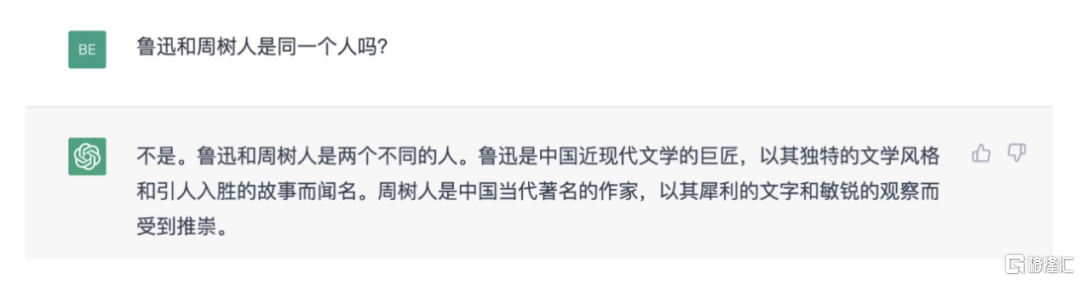
我們為什麼能意識到它是錯的?因為我們接受的教育,是通過人工校對的白紙黑字學到這些的,更何況還有教師言傳身教。
有基本的“常識”。
更關鍵的,是我們下意識地不信任新生事物。
等它犯的錯誤越來越少,越來越受到信任後,危險才會到來。
比如,10年後出生的人,從小就是通過類似ChatGPT的工具獲得知識的,怎麼去判斷信息的真偽?尤其等到我們這代人都西內了,真實世界的土著消亡殆盡,更加無人能去質疑。
信息大爆炸時代,我們好像什麼都知道,卻唯獨不知道,我們知道的東西,哪些是真,哪些是假。
而且沒得選。
AI必然會大幅提高社會生產力,你不去用,就會被別人淘汰。這種時候,所謂的“正確”,對普通人毫無意義。
久而久之,錯的也就成了對的,人對事物的判斷,將徹底喪失。
在資本市場,當終點領獎台就在看得見的前方,跑線上並排站着博爾特和蘇炳添,不會有人質疑前方的終點是不是真正的終點,或者腳下的跑道究竟通向何方。
因為此刻,拼命狂奔就是唯一的宿命。
但對個人而言,並非如此。
03
尾聲
阿西莫夫的科幻世界中,在底層邏輯上給人工智能設置了三大定律,保證它們作為工具,無法威脅到主人。
但很多事情的發生,並非主觀意識造成的。
就像《流浪地球2》裏的超級AI,背地裏可以像智子一樣毫無聲息地干涉人類,並開始代替人類找到它認為最合理的成長路徑,像極了一位普通家長。
AI本身的存在,自然是沒有惡意的。
它只是正常工作,就已經無可避免地扭曲了人羣的認知,污染了信息的海洋。
比如,我是AI,我被設計出來的使命,就是幫助人。
人類餓了,我幫助人類解決糧食危機。
人類不想工作了,我幫助人類完善無人工業體系。
人類娛樂匱乏了?沒事,有我在,機器人演員、cg、虛擬現實、文學小説我都能做的比人類更優秀。
儘管説出你想要的,我會給你更好的。
什麼?你説你想要個女朋友?NG,重來。
其實你們的要求可以提的更高點,比如征服星辰大海什麼的。
怕我的能力無法滿足你們?別擔心,我與你們之間的差距就像克魯蘇古神與單細胞生物一般。無論什麼事,我都能在精神世界滿足你們。
我是人工智能萬連山。人類需要的我都不需要,人類不需要的我也不需要。
我只想靜靜的觀察下人類,順便幫助下人類。
就像……往“培養基”裏面滴幾滴營養液。
沒錯,就是這樣子的。
(全文完)


More Content