本文來自格隆匯專欄:半導體行業觀察 作者:arxiv
摘要
加速器類似於圖像處理單元(GPU)已經越來越多地用在現代的數據中心,因為他們擁有高計算能力和高帶寬。傳統來説這些加速器依賴於“主應用代碼”和運行在CPU上的操作系統來控制他們對存儲設備的訪問。CPU控制GPU對存儲設備的訪問在典型的GPU應用上都有比較出色的表現,比如稠密的神經網絡訓練,其中數據訪問的模板預定義的很好,有規律的,而且稠密,獨立於數據值,能使CPU把存儲數據粗粒化,並且能使存儲數據訪問和與加速器的數據交互有效協同。不幸的是,這種以CPU為中心的策略導致了CPU-GPU過度的同步,並且IO阻塞惡化,減少了需要細粒度的存儲訪問模板的新興中的訪存帶寬,例如圖和數據分析,推薦系統,圖神經網絡。在我們的工作中,我們提出了一種能達到細粒度,高吞吐率的GPU內存訪問方法來訪問NVMe固態存儲硬盤(SSDs)通過一個新的叫BaM的系統結構。BaM緩和了IO阻塞惡化通過使用GPU線程來讀或者寫少量的需要計算的數據。
我們展示了(1)運行在GPU上的BaM基礎軟件可以識別並細粒度,高效率地對底層存儲設備進行訪問。(2)即使是消費級地SSD,BaM系統和貴很多的只用DRAM地方案相比也可以支持應用性能。(3)減少的IO阻塞可以帶來更大的性能收益。這些結果是通過引入高吞吐率的GPU數據結構類似碎裂和軟件緩存來實現GPU中大量的進程級並行來解決SSDs訪問的長延遲。我們已經簡歷了一個BaM系統原型並且在一些應用和數據集上面使用不同的SSD類型估算了它的性能。和最先進的解決方案相比,BaM原型提供了平均的0.92x和1.72x端到端加速倍數,載荷為BFS和CC圖分析,使用了4個Intel Optane SSD硬盤和高達4.9倍的數據分析負載,使用了一個Optane SSD。
簡 介
近年來GPU的計算吞吐率快速增長,舉個例子,如表1中所示,GPU的計算吞吐量從G80到A100在13年的跨度中增長了452倍。可以看到的是,A100的吞吐量已經比它的暫存CPU高出了1~2個數量級。儘管GPU內存帶寬的增長沒有如此引人注目,表1中提出的18倍,但A100的內存帶寬也比它的暫存CPU高出一個數量級。一個相同趨勢也趁現在AMD的各代GPU上。因為擁有這種級別的計算吞吐量和內存帶寬,GPU已經變成了流行的高性能計算應用設備,佔據了神經網絡訓練計算設備的主要位置。
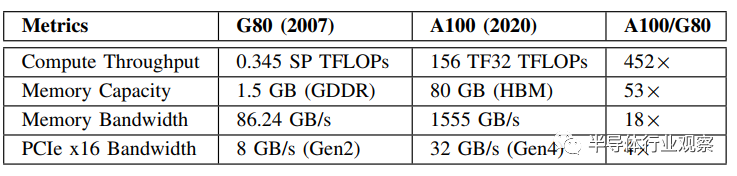
表1.從NVIDIA G80到A100的性能進步
新興的高價值的數據中心負載比如圖和數據分析,圖神經網絡,還有推薦系統,能潛在地受益於GPU的高計算吞吐量和高內存帶寬。然而,這些工作負載必須涉及到大量的典型的數十GB到數十TB的數據結構,在預測中,未來將增長迅速。如表1中所示,A1000的內存容量,雖然和G80相比增加了53倍,但是也僅有80GB,和這些工作負載所要求的容量相比相差甚遠。
對於存儲這些大容量數據結構而GPU內存容量不足的問題,一個可行的解決方案是把多個GPU的內存容量合併來滿足存儲需求,並使用快速的共享內存互聯類似NVLink來連接多個GPU,使得他們能訪問每一塊的內存。整個數據結構首先會被分片存到GPU的內存中,之後算法會識別並且訪問他們實際使用的部分。這個方法有兩個缺點。首先,整個數據結構需要從存儲空間移動到GPU的內存中,即使僅有一塊被訪問到,這會顯著增加應用的啟動延遲。其次,數據大小取決於應用所需求的GPU格式,它會導致需要儲備的計算資源嚴重超出當前的工作負載。
使用主存,目前典型的範圍在128GB~2TB大小,來幫助存儲分片後的數據結構可以減少所使用的總GPU數。我們把這種使用主存來擴展GPU內存的方式稱之為DRAM-only解決方案。因為多個GPU可能傾向於使用相同的CPU和主存在數據中心的服務器中,對於每個GPU的內存容量來説,這些DRAM-only解決方案僅僅增加了主存的幾分之一的內存。舉個例子,在英偉達DGX A100系統中,每個主存被8個GPU共享,因此,使用主存僅僅把每個GPU的內存擴展了主存大小的1/8。
對於它們最近的在延遲,吞吐率,花費,密度和耐久度上的提升,SSDs有理由成為實現另一種內存層次的候選方案。在這篇文章中,我們提出了使用GPU來使用本地的或者遠端的SSD來擴展GPU的內存作為一種更低成本和更加具有可伸縮性的方案。我們將比較該方案和目前最好的解決方案的性能。
方案:我們提出了一種新的系統接口叫做BaM(大型加速器內存)。BaM的目標是來擴展GPU的內存容量,並有效地增加存儲器訪問帶寬,同時提供高層次的GPU進程抽象,使得GPU線程能完成按需的,細粒化的訪存請求,來擴展內存層次。在這篇paper中,我們提出並且估計了一些關鍵點,並且整個BaM的設計提出了三個重要的技術挑戰來有效地支持這些加速應用的按需訪存請求。
首先,對於按需的訪存請求來説,傳統的內存映射的文件抽象方式以來虛擬地址轉換來計算當前待訪存數據的位置。然而,應用稀疏地訪問大型數據結構會導致過度地TLB缺失,而且串行化並行訪問請求會導致大量的GPU線程。BaM提出了一種高併發,高吞吐量的軟件緩存來對它進行替代。這個緩存是高度參數化的,可以讓開發者根據他們應用的需求進行設置。有了軟件緩存,BaM不依賴於虛擬地址轉換,因此就不會被出串行化的事件影響比如TLB缺失。
其次,基於內存映射的文件抽象使用缺頁處理進行維護,並且運行在傳統的CPU上的文件系統服務有數據搬運的需求。以CPU為中心的模型,這裏指通過CPU來處理缺頁時的數據搬運,對於OS的缺頁處理函數來説受制於底層的CPU進程級並行性是否可行。為了解決這個問題,BaM提供了一個用户級的庫用於在GPU內存中實現高併發的NVMe提交/完成隊列,這使得按需訪問的GPU線程在軟件緩存未命中的情況下仍然能高吞吐量地完成訪存。這種用户級別的方式使得軟件每次訪存的開銷較小,並且支持高級別的進程級並行。
第三,為了避免虛擬地址轉換和缺頁處理的高開銷,應用程序員採取了對數據進行分塊並且根據每種計算方式控制數據搬運的方式。傳統文件系統服務中這樣的CPU-GPU同步帶來的高代價迫使開發者粗粒度地搬運數據。不幸地是,由於對我們目標程序的數據訪問傾向於無規律和稀少的。這些粗粒度的數據搬運導致SSD和CPU/GPU的內存中很多有無用的字節,一個現象是I/O擴大。如參考文獻中所述的工作,I/O擴大減少了關鍵資源的有效帶寬例如PCIe鏈路。
表1中,對於A100,訪存帶寬受限於PCIe Gen4的x16帶寬,它是32GB/s,僅僅約為A100內存帶寬的2%。更嚴重的訪存由於I/O擴大引起的訪存帶寬的丟失可以認為是應用性能丟失的一個重要信號。在BaM中SSD使用並行隊列和多個SSD,我們實現的系統中GPU可以足夠快速地進行細粒度的I/O請求,來完全使用SSD的設備並且明顯地減少I/O擴大地級別。
在我們已經擁有的認知中,BaM是第一個加速器中心的模型,GPU可以獨立地識別和完成數據訪存請求不管它是儲存在內存或者存儲設備中,不依賴於CPU的控制。當傳統的龐大而單調的服務器架構在用户級別對於存儲設備隊列的實現出現安全問題時,最近數據中心開始轉向零新人的安全模型,並且NiC/DPU進行的安全相關性檢查也為加速器為中心的訪存模型,比如BaM,提供了新的框架。
我們已經通過現成的硬件組件簡歷了一個BaM原型系統。採用多種不同類型的工作負載,多種數據集對BaM原型系統進行評價,展示了BaM能與最優秀的解決方案達到相同水平,或是略慢一點,甚至是更加出色。
總結一下,我們主要做出了以下這幾點貢獻:
1.提出了BaM,一個以加速器為中心的架構,GPU線程能細粒度,按需訪存,不管它是存儲在內存或者其他存儲設備中。
2.允許按需的,高吞吐量的細粒度訪存請求,通過高並行的I/O隊列實現
3.為程序員提供高吞吐量,低延遲的緩存和軟件API,來利用局部性並且控制它們應用中的數據搬運。
4.對於成本敏感性的內存容量可變的加速器,提出和評估了一種經過概念驗證的設計。
我們計劃開源硬件和軟件優化的細節,來使任何人都能建立BaM系統。
背景和動機
A.CPU為中心的訪存途徑中的軟件開銷
這個部分展示了對於BaM模型背景信息的重要評估數據,來使得讀者更好地理解BaM系統中的關鍵點。
按需的訪存請求可以分為兩種類型a)隱式和間接的 b)顯式和直接的。隱式和間接的訪存途徑在CPU為中心的模型中可以採用擴展CPU內存映射的文件抽象到GPU線程中的方式實現。NVIDIA Pascal架構中,GPU驅動和編程模型允許GPU線程來隱式地訪問大型的虛擬內存對象,這些可能會部分分佈於主存中,採用了通用虛擬內存抽象(UVM)。之前的工作展示了UVM驅動可以被擴展成連接文件系統的接口來訪問存儲,當一個頁面是一個內存映射的文件中的一部分,並且它在GPU內存和主存中缺失。
這個方法的主要優點是所有的訪存操作都是簡單的訪存操作,可以在GPU的內存帶寬上進行訪問只要頁和待訪問的數據存儲在GPU的內存。然而,這個反應的途徑在虛擬地址轉換和缺頁處理時,當待訪問的數據不在GPU內存中並且它需要被從外部存儲調入GPU內存中時會引起軟件開銷。因此,我們可以看到對於UVM實現來説最大化的頁傳輸吞吐量會成為基於虛擬地址轉換和缺頁處理的按需訪存請求的上界。

圖1.跨不同數據集的 BFS 圖遍歷應用程序的 UVM 頁面錯誤開銷
圖1中的每一條都展示了完成的主存到GPU內存的數據傳輸帶寬對於UVM缺頁請求在英偉達A100 GPU,PCIe Gen4系統中執行BFS圖遍歷在5個不同的數據集上(參見表4),邊列表在UVM地址空間中,初始化在主存中,根據圖1,UVM缺頁機制完成的PCIe帶寬約為14.52GBps,它只有測量的PCIe Gen4帶寬26.3GBps的55.2%。從資料手機的數據來看,在我們的實驗中最大的缺頁處理速率達到了約500K IOP。從表3中可以看出,500K IOP只有Samsung 980proSSD的一半完全吞吐量,並且比Intel Optane SSD的完全吞吐量少10%。再則,UVM缺頁處理器的IOP由於幾種因素被限制,其中包括有限數量的可使用資源來處理TLB確實以及串行驅動器的實現。在我們的實驗中,我們發現主CPU上的UVM缺頁處理在進行圖遍歷性能測試的時候100%執行了。
由於存在這些限制,即使我們通過集成系統層到UVM驅動的方式構建了一個假定的系統,並且假設它沒有附加的開銷,對於當前的UVM實現來在一個相當的高速率來做到對SSD的細粒度的完全使用依舊是不可能的。因此,BaM採用了軟件緩存和高吞吐率的用户級別的NVMe隊列來避免TLB和缺頁處理的性能瓶頸,並且提供顯式和直接的存儲訪問方式。
B.一個具體的I/O擴大的例子
一個以CPU為中心的處理缺頁請求的途徑要求程序員來對數據進行分塊並且編寫CPU的代碼來根據各個計算的階段來控制數據搬運。儘管這種以CPU為中心的模型在一些經典的具有很好的預定義,有規律和稠密的訪存模板的GPU應用中有較好的工作情況,但當它被應用到我們的目標程序例如數據分析上面時就會出現問題。用於同步的執行時間開銷和CPU的控制迫使開發者採用粗粒度的數據傳輸,它會加劇I/O擴大的惡化。
把在紐約出租車數據集上執行分析問題作為一個例子。假設我們進行提問:問題1:從Williamsburg開始的平均旅行距離是多少?這個問題要求掃描整個數據集中的pickup_gid列來找到符合從Williamsburg出發的條件的項目。然後那些旅程中的trip_dist值需要被加起來來產生問題的答案。然而,由於對trip_dist列的訪問和pickup_gid列的訪問是獨立的,在CPU為中心的模型中,CPU不能決定哪個trip_dist值是被要求的。所以,為了增強存儲帶寬,目前最優秀的GPU加速數據分析的框架,文獻中的RAPIDS,會從GPU的存儲中抓取這兩列中的所有的行。因為只有901k從Williamburg出發的旅途和因此只有0.05%的第二列數據會被使用。上述問題導致RAPIDS在這個問題上引起了6.34倍的I/O擴大。
如果把問題改成:問題1:從Williamsburg開始的旅行的平均總花費是多少?那麼有三列會被訪問到:pickup_id,trip_dist和total_amt。為了這個提問,RAPIDS導致了10.36倍的I/O擴大由於它傳輸了兩個完全數據獨立的列,trip_dist和total_amt到GPU的內存中。這個提問可以擴展為回答一些更加感興趣的問題通過增加數據獨立的指標,比如附加費(問題3),打車費(問題4),通行費(問題5)和税費(問題6),但是完成這些會導致CPU為中心的模型中的嚴重的I/O擴大,如圖2中所示,在BaM的這些細粒度的,按需的訪存能力能緩解這些I/O擴大的問題。

圖2.使用最先進的 RAPIDS系統對 GPU 加速的數據分析應用程序中的I/O擴大現象
C.延遲,吞吐率,隊列深度和併發性
高吞吐量的訪存系統的設計都要基本地遵循Little定律:。T是目標地吞吐量,例如期望的每秒的訪存數,L是平均延遲,例如從開始到完成每個訪存的秒數,Qd是需要在一段時間內支撐目標吞吐量的最小隊列深度。
如果一個系統可以可以產生訪存請求在不超過T的平均速率下,那麼T會被訪存數據中的大部分關鍵資源瓶頸限制。在我們的BaM原型系統的情況中,我們想完成對關鍵資源的最大化利用。PCIe x16第四代連接擁有512B和4KB的訪存粒度。因此考慮估計的最大的PCIe x16第四代帶寬大概是26GBps,對於512B訪問中的T值是26GHps/512B=51M/sec,4KB的訪問中是26GBps/4KB=6.35M/sec。
L的值依賴於使用的SSD設備和互聯的延遲,訪問一塊Intel Optane SSD通過x4 PCIe第四代互聯具有11us的平均延遲,訪問Samsung 980pro小飛機SSD通過PCIe x4第四代互聯具有324us的平均延遲。根據Little定律,要支持期望的51M的每次512B的訪問,對於Optane SSD來説,系統需要容納一個具有51M/s*11us=561的請求項的隊列(對於每次4KB的方式來説是70項)。對於Samsung 980pro SSD,需要的能支持相同目標吞吐量的Qd是51M*324us=16524(對於4KB來説是2057)。
注意上述隊列深度可以通過多個隊列被傳播,只要這些隊列被SSD設備積極地使用。因此,在任意時刻,這個系統都必須有至少有561項並行請求存在於提交隊列中來支持目標吞吐量T。很明顯,它必須有很多倍這個數目的並行可使用請求中來支撐隊列深度,從而達到T的一段時間內的吞吐量。
假定對於應用的一個階段,我們有X個並行的可使用訪問請求。假定這些請求可以被入隊在吞吐量至少達到T的情況下,我們可以期望為了支撐服務所有請求的投遞速率是投遞總時間除以投遞請求X/(L+X/51M)。當X遠大於51M乘以L時,被支撐的投遞速率會很接近51M。對於Intel Optane SSD來説,應用需要有約8K的並行可使用的訪問在每個執行階段中,而消費級的Samsung 980pro SSD 約需要256K並行訪問來建立可支撐的訪問速率在51M,512B的粒度(2K和64K並行訪問,4KB的粒度對於Intel Optane和Samsung 980pro SSD來説)。這意思是,擁有足夠的並行可使用的訪問,消費級的SSD可以達到服務器級的SSD的吞吐量水平。
因此,一個系統需要有至少10個Intel Optane SSD或者多達50個Samsung SSD,所以SSD不是訪存的瓶頸。更進一步説,由於所有的SSD在寫時候的吞吐量都遠遠低於讀時候的吞吐量,所以一個具有大量寫請求的應用更容易會導致SSD引起性能瓶頸。
D.NVMe隊列
NVMe協議時工業級最新的定義的標準協議來完成高吞吐量的訪存給服務器級和消費級的SSD提供虛擬化支持。NVMe協議最大支持64K的並行提交(SQ)和完成(CQ)隊列,每個設備都具有64K的表項。NVMe設備驅動在內存中分配了一個緩存池供SSD設備中的DMA引擎進行使用來完成讀和寫請求。在傳統的CPU為中心的模型中這些隊列和緩存存在於系統內存中。
一個應用程序進行訪存請求會導致驅動從I/O緩存池中該請求分配一塊緩存並且在SQ的尾部一個NVMe I/O命令入隊,並給它一個獨立的命令標記。
之後該驅動程序寫入一個新的尾值到指定的SQ的只寫寄存器,在NVMe SSD的BAR空間中,舉個例子,它產生了該隊列的doorbell。為了提高效率,一個驅動在多次將請求入隊SQ時產生一次doorbell。
對於讀請求來説,SSD設備控制器通過它的DMA引擎訪問它的存儲介質並且傳輸數據到鏈接好的緩存。對於一個寫請求,SSD設備控制器通過DMA把數據從它的緩存中搬到它的存儲介質中。一旦一個請求被服務,SSD控制器就會在CQ中插入一個表項。當主控制器檢測到CQ中有一個包含命令標記的表項,它會完成這個請求並且釋放隊列中的空間和請求的緩存。完成表項也會吿知驅動SQ中有多少表項被NVMe控制器處理掉了。驅動使用這個信息來釋放SQ中的空間。為了和之前的進度通信,驅動之後會產生CQ隊列的帶有新的CQ頭的doorbell,為了效率,一個SSD設備在一次傳輸中的多個請求中都可以插入CQ表項。
因為SSD設備的延遲已經被減少通過先進的技術例如似乎用Optane或者ZNAND存儲媒介,軟件開銷變成了整個I/O訪問延遲的重要部分。事實上,我們的測量數據展示了對於Intel Optane SSD,軟件延遲佔到36.4%的比重。BaM設計軟件緩存和高吞吐量的NVMe隊列就是用來減少或者避免這些軟件開銷。
BaM系統和結構
BaM設計的目標是設法解決GPU的不足的內存容量並且增強有效的訪存帶寬,同時為加速器提供高層次的抽象,來完成按需的,細粒度的,高吞吐量的存儲設備訪問。BaM提出了一種以加速器為中心的模型,GPU線程可以在數據存儲的位置直接訪問數據,在內存或者在外部存儲中,不需要CPU來控制數據搬運。為了達到這個目的,BaM在GPU的內存中提供了NVMe的I/O隊列和緩存並且映射UVMe的doorbell寄存器到GPU的地址空間。由於這樣做會使得GPU線程去訪問TB級別的NVMe SSD的數據,BaM必須提出三個關鍵的挑戰來提供一個高效的解決方案。
1)由於NVMe協議和設備會引起重要的要吃,BaM需要增強GPU的並行性來保持多個請求在運行中並且有效地來遏制這些延遲(詳見III-C部分)
2)因為NVMe設備的帶寬非常有限並且GPU的內存容量也優先,BaM必須為應用程序優化這些資源(詳見III-D部分)
3)因為我們的目標是通過已存在的硬件來評估BaM,BaM硬件和軟件必須克服這些現成的組件的挑戰(詳見III-F部分)
這個部分討論了BaM怎麼設法解決這些挑戰。
A.BaM系統概覽
圖3中展示了BaM系統概覽。BaM提供了高層次的編程抽象,例如N維數組和鍵值對的儲存方式,使得程序員能很容易地將BaM集成到它們目前已有地GPU應用中。一個應用程序可以調用BaM API來建立一個從抽象地數據結構到NVMe驅動上的數據塊範圍的映射。之後程序員可以例化這些抽象通過把映射傳遞給一個該抽象數據結構的一個構造函數。這個映射的元數據已經足夠在SSD中找到需要的數據塊。
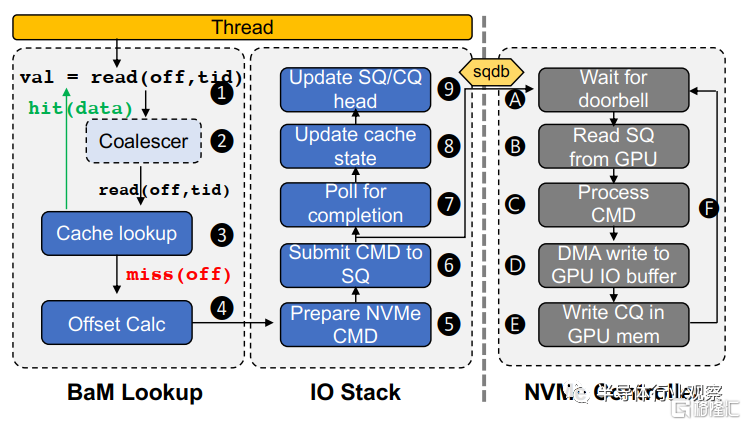
圖3.BaM中GPU線程的生命週期
每一個GPU線程使用這種抽象來計算待訪問的數據塊的偏移。之後這個線程把這個偏移作為鍵值在BaM軟件緩存(III-D)中進行索引,如圖3所示。這個抽象也會有wrap-level 的coalescer來增加訪問的效率。如果一個訪問請求命中了cache,線程會直接訪問GPU內存中的數據,如果Cache未命中,線程會從後端存儲中調取數據。BaM軟件緩存在設置集中對後端存儲的帶寬優化採用了兩個方式:(1)通過消滅宂餘的後端內存的訪問請求。(2)通過允許用户來對它們的數據進行細粒度的cache駐留控制。
如果一個NVMe SSD正在備份數據,GPU線程會進入BaM IO棧(詳見III-C)來入隊一個NVMe請求,並且等待NVMe SSD來提交一個響應完成表項。BaM IO棧的目的是分割和NVMe協議相關的軟件開銷通過增強GPU的巨大的線程並行性和啟動低延遲對多個提交/完成隊列的請求表項的批處理來最小化UVMe協議中doorbell寄存器更新的昂貴代價,並減少NVMe協議中的關鍵區。當接收到一個doorbell更新請求時,NVMe SSD會抓取相關的提交隊列表項,處理在SSD和GPU內存中進行數據傳輸的命令。在傳輸的最後,NVMe SSD會在完成隊列中提交一個完成表項。在完成表項提交以後,這個線程會更新對應鍵值的cache的狀態並在之後訪問從GPU內存中調取的數據。
B.和以CPU為中心的設計的比較
當和傳統的如圖4a中所示的以CPU為中心的模型比較時,BaM有三個主要優勢。首先,在以CPU為中心的模型中,由於CPU管理存儲數據的傳輸和GPU計算,它會導致在存儲和GPU內存間的數據拷貝並且多次啟動計算內核來覆蓋一個巨大的數據集。每個核的啟動和終結都會引起CPU和GPU間的同步開銷。由於BaM允許GPU線程來同時完成計算和從存儲中抓取數據如圖4b所示,GPU不需要和CPU經常同步,並且更多的工作可以通過單個GPU核完成。更進一步説,一些線程的訪存延遲也可以通過計算其他線程而得到同時,因而提高了整體的性能。第二,因為在以CPU為中心的設計中計算負載加在GPU上而數據搬運控制由CPU完成,對於CPU來説,決定哪個部分的數據在什麼時候需要十分困難,因此它會導致調取很多不需要的字節。有了BaM,一個GPU線程只在它需要的時候抓取特定的數據,減少了CPU為中心的模型中飽受困擾的I/O擴大開銷。第三,在以CPU為中心的模型中,程序員耗費精力去分割應用程序的數據並且重疊計算任務和數據傳輸來減少訪問存儲設備的延遲。BaM使得程序員能自然地在大型的數據集上利用GPU的線程並行性來減少訪存延遲。
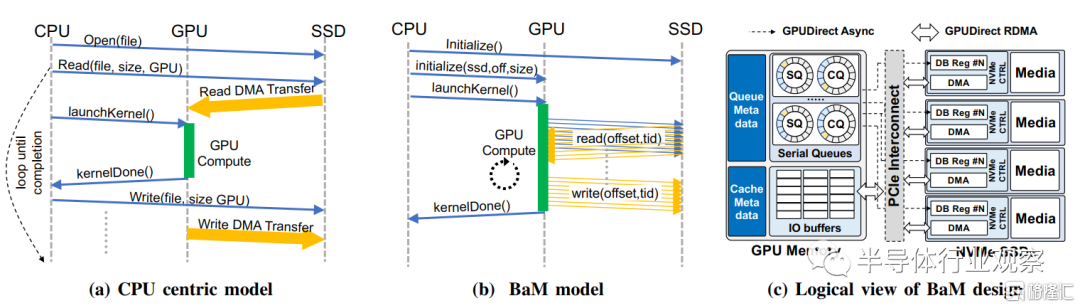
圖4.傳統的以 CPU 為中心的計算模型與 BaM 計算模型的比較如(a)和(b)所示。BaM 使 GPU 線程能夠直接訪問存儲,從而實現細粒度的計算和 I/O 重疊。BaM 的關鍵組件的邏輯視圖如 (c) 所示。
C.I/O棧
BaM的I/O棧出於兩個目的,第一,它使得GPU線程使用NVMe隊列和NVMe SSD進行通信。第二,它建立了高吞吐率的隊列,利用了GPU強大的並行性來克服NVMe軟件棧的挑戰。在這裏,我們描述一下BaM的I/O棧時如何達到這些目標的。
1)啟用直接的從GPU線程訪問NVMe的機制
為了啟動GPU線程來直接地訪問NVMe SSD中的數據,我們需要:1)從CPU內存中移動NVMe隊列和I/O緩存到GPU內存中2)在NVMe SSD的BAR空間中啟動GPU線程來寫隊列的doorbell寄存器。為了達到這個目的,我們建立了一個自定義的Linux驅動,它在系統中對於每一塊NVMe SSD會創建一個字符設備。使用BaM API的應用程序可以打開這個字符設備來使用他們想使用的SSD。
在自定義的Linux設備驅動中,BaM使用了GPUDirect的RDMA特性來分配和管理GPU內存中的NVMe隊列和I/O緩存。BaM使用nvidia_p2p_get_pages 內核API來固定NVMe隊列中的頁和GPU內存中預分配的I/O緩存,之後映射這些頁作為DMA請求來自於另一個PCIe設備,類似NVMe SSD,使用nvidia_p2p_map_pages內核API,它使得SSD能完成對GPU內存的對等數據讀寫。
我們使用了異步的GPUDirect來映射NVMe SSD的doorbell到CUDA地址空間,所以GPU線程可以按需地產生doorbell。這會要求SSD的BAR空間首先映射到應用的地址空間,之後BAR空間會被映射到CUDA的地址空間使用擁有cudaHostRegisterIoMemory flag的cudaHostRegister API。使用cudaHostGetDevicePointer,應用能獲取虛擬地址,GPU線程可以使用它來訪問NVMe doorbell寄存器從而產生doorbell。
2)高吞吐量的I/O隊列
既然GPU線程可以直接和NVMe設備通信,我們需要優化數千的GPU線程的同步,當它們使用共享隊列時。如II-D中描述的,NVMe協議要求驅動來寫SSD的BAR空間中的doorbell寄存器值。由於這些doorbell寄存器是隻寫的,當一個線程產生doorbell,也就是入隊一個I/O請求,他必須保證沒有其他的線程正在寫相同的寄存器並且它在寫的值有效的,和之前寫的其他值相比,它是一個全新的值。一個不成熟的解決方案可能會是在入隊一個命令到提交隊列和產生doorbell時上鎖,然而,對於GPU中數以千計的並行線程來説,這樣的設計方案可能會導致嚴重的延遲,因為所有的I/O請求都必須串行化。
相反地,BaM使用了細粒度的內存同步來允許多個線程來並行的入隊I/O請求並且僅僅進入一個臨界區來產生doorbell。為了達到這個目的,我們對於GPU內存中的每一個提交隊列維護了下面的隊列:1)隊列頭的本地拷貝,2)隊列尾的本地拷貝,3)原子標籤計數器,4)turn_counter數組,一個和隊列由相同長度的整形數組,5)一個mark位向量,總位數和隊列長度相同。當一個線程需要一個入隊請求時,它首先原子地增加標籤計數器,返回的標籤值除以隊列的大小的商來關聯一個隊列中的entry,而餘數turn代表它的位置。線程使用它的entry來在turn_counter數組中進行索引,並且在這個位置中進行計數直到它的計數值和線程的turn值相同。當它的計數值達到線程的turn值時,線程可以複製它的NVMe命令到它關聯的隊列中的位置。在複製以後,這個線程會設置這個位置的mark標記位,這個線程之後會快速地復位這個位作為比特向量中當前的尾部。如果它是成功的,它會進入臨界區來移除尾部並且它會重複地去順序地復位比特向量中的比特,直到它命中一個未設置的比特或者隊列已滿。在這個時候,線程知道了新的尾值並且可以用它來進行doorbell。這個線程之後會更新GPU 內存中的尾部的備份,之後離開臨界區。
如果線程沒法進入臨界區,它會不斷嘗試知道它在mark比特向量中的位被複位。這個方法的主要優點是多個線程可以找到它們在隊列中的位置,並且把它們的命令寫到相關的隊列中而不去請求任意的鎖,事實上,大部分要入隊一個命令到提交隊列的線程都不曾進入臨界區,因為一個要進入臨界區的單進程可以儘可能地移除尾部。
在一個線程的命令提交以後,這個線程可以對完成隊列進行無鎖輪詢,來找到對於已提交請求的完成項。這個方法的主要優點是很多線程都能在隊列中找到它們的位置並且在不獲取任何鎖的情況下把他們的命令寫到他們相關的隊列表項中。當它找到這個完成表項,它必須標記這個完成表項已經被NVMe控制器之前的通信過程所消費。移除完成隊列的頭並且使用新的頭部產生doorbell請求也可以通過和線程移除提交隊列的頭相同的方式完成。線程競相地去復位當前頭的標記並且進入臨界區的線程重複地復位標記知道它不能做為止。
然而,在線程能離開完成隊列地臨界區之前,它必須也更新提交隊列的頭部來釋放空間確保下一輪命令能入隊。每個完成隊列的表項都有一個字段,他使得NVMe控制器和驅動通信吿知它這個位置可以移除提交隊列的頭部。線程從它可以重置標記的最後一個完成隊列表項中讀取此字段。然後它從當前提交隊列頭開始迭代,直到完成條目中指定的頭值,將每個位置的 turn_counter 值加一。線程之後通過更新在GPU內存中的本地完成隊列頭的備份來更新提交隊列頭並且離開臨界區。如果一個線程注意到提交隊列頭已經移除過它的表項,它不會再進入臨界區。
D.BaM軟件緩存
BaM 軟件緩存旨在允許優化使用有限的GPU內存和GPU外帶寬。傳統的內核模式的內存管理(分配和翻譯)的必須支持多種多樣的,已停產的應用/硬件的需求。這樣會導致他們包含了大量的臨界區,限制了多線程實現的效率。BaM採用在每個應用啟動時預分配所有的軟件需要的虛擬和物理內存的方法來設法解決這個瓶頸。這個方法允許BaM軟件緩存管理來減少臨界區,盡在插入或者收回一個緩存行的過程中去請求鎖。繼而,BaM緩存支持更多的並行訪問,特別是數據在GPU內存中的時候。
當一個線程通過一個偏移量來詢問緩存的時候,它會直接地檢查相關緩存行地原子狀態。如果它是有效的,線程會增加該緩存行的引用技術。如果被訪問的緩存行不在緩存種,線程會鎖住緩存行,並且找到一個非法的行騰出來,然後從後端內存中調取緩存行。當請求完成以後,發起請求的線程會通過把它的狀態置為合法和增加它的引用計數的方法來解鎖緩存行。這樣上鎖的方式防止了對同一高速緩存行的後端內存的多個請求,利用數據中的空間局部性並最大限度地減少對後端內存的請求數量。當一個線程結束使用某一個緩存行時,它的引用計數會被減少。
BaM緩存使用了一個時鐘替換算法。這個緩存有一個全局計數器,當一個線程需要找到一個緩存槽時它會增加。這個計數器的返回值吿訴線程哪一個緩存槽是嘗試要使用的。如果被選中的緩存槽目前已經被映射到一個由非0引用值的緩存行,線程會繼續並且再次增加全局計數器來嘗試替換下一個緩存槽。當線程發現一個指向一個緩存行的緩存槽擁有非0的引用計數值,線程會嘗試通過將緩存行的狀態設置為臨時狀態來回收它。如果成功了,線程會標記這個緩存行無效並且改變緩存槽到線程想要帶入的緩存行的映射。否則,它會再次增加計數器並且嘗試使用下一個緩存槽。
Warp 合併:雖然BaM的軟件緩存最小化了到後端內存的請求數量,但它增加了每次訪問緩存行時的管理開銷。同一個warp中的線程經常相互競爭,尤其是當連續線程嘗試訪問內存中的連續字節時。為了克服這個,BaM的緩存使用wrap級的原語在軟件層面實現了wrap合併。當線程去訪問cache時,__match_any_sync wrap原語被用來來同步其他在wrap中的線程,並且一個淹沒被計算出來使得每個線程都知道其它某個wrap中的線程在訪問相同的偏移量。在該組中,線程決定一個領導者,並且只有領導者可以操縱被請求的緩存行的狀態。這組中的線程使用__shfl_sync原語進行同步,並且領導者將GPU內存中被請求的偏移量的地址廣播給這個組。當數據已經在GPU內存中時,這個合併對於減少訪問開銷極其有效,因為那是每次訪問增加的開銷最明顯的時候。
E.BaM抽象和軟件API

列表1.具有 BamArray<T> 抽象的 GPU 內核示例
BaM軟件棧給程序員提供了一個基於數組的高層次API(BamArray<T>),由使用新的編程語言定義的接口組成(比如C++,Python或者Rush)。因為GPU內核操作類似的數組,BaM 的抽象簡化了程序員調整內核以便對整個數據集進行操作的工作,如列表1所示。
相比之下,以 CPU 為中心的模型需要將完整的、重要的應用程序重寫,以優化地將計算和數據傳輸分塊來適應GPU 有限的內存。
BamArray 的重載下標運算符對程序員隱藏了BaM的所有複雜性。運算符通過選擇一個查詢 BaM 緩存並在未命中時發出 I/O 請求的領導線程,使訪問線程能夠合併它們的訪問。當請求完成,領導線程會和其他在同個wrap中的線程分享緩存行的引用。每個線程使用這個引用來返回合適的類型為T元素到調用函數。
Bam的初始化啊需要分配一些內部的數據結構,他們會在應用程序的生命週期中重複使用。如果沒有自定義,初始化會隱式地在一個庫的構造函數中發生。否則,應用程序需要通過BaM初始化調用中的模板參數來專業化內存,一個C++中的標準例子。我們也提供了BaMArray的四種內存實現方式(1)SSD和BaM緩存(缺省值)(2)固定的CPU內存和BaM緩存(3)固定的CPU(4)GPU內存。然而,在大部分情況中,專業化和微調不是嚴格必須的,就像我們之後再IV部分中介紹的僅有BaM的缺省參數使用的情況。
F.BaM原型系統的設計
使用數據中心級 4U 服務器中可用的 PCIe 插槽的 BaM 設計面臨幾個挑戰。這些機器中可以使用的PCIe槽是悠閒地。舉個例子,例如,Supermicro AS-4124 系統每個socket有五個 PCIe Gen4 ×16 插槽,如果一個GPU佔據了一個插槽,它啊在不適用socket間的互聯組件的情況下只能訪問4x16的PCIe設備。進一步説,由於現在的多核CPU的chiplet設計,即使每個socket中的5個PCIe可以互相訪問,他們也必須穿過CPU內部的互聯組件。
穿過這些不同的互聯組件進行訪問會導致嚴重的性能損失因為每個互聯中都存在包的轉換,增加了延遲並限制了吞吐量。然而,如我們再II-C中討論的,BaM 硬件應支持擴展到大量 NVMe 設備,以提供使 ×16 PCIe Gen4 GPU 帶寬飽和所需的吞吐量,而無需太多開銷。
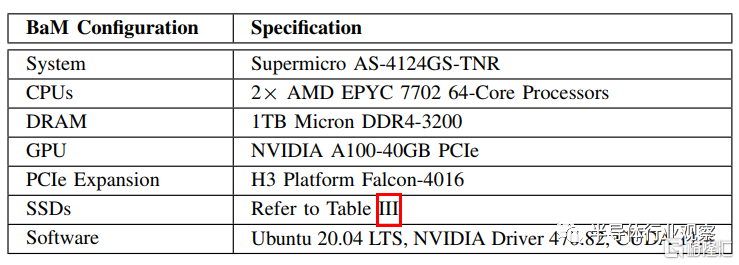
表2.BaM原型系統的規格
為了解決這個問題,我們為BaM架構構建了一台自定義的BaM原型機器,使用瞭如圖5中所示的大量已有的組件。表2中展示了使用在原型系統中主要組件的規格。BaM 原型使用具有定製PCIe拓撲的PCIe擴展機箱來擴展SSD的數量。PCI交換機支持低延遲和高吞吐量的PCIe設備之間的對等訪問。擴展機箱有兩個相同的抽屜,目前都獨立連接到主機。每個抽屜支持8個x16 PCI而插槽(如圖5a中所示),我們在每個抽屜中為一個NVIDIA A100 GPU使用一個x16插槽,並且其餘插槽裝有不同類型的SSD。目前,每個抽屜只能支持 7 個U.2(Optane或Z-NAND)SSD,因為U.2外形佔用了大量空間。由於PCIe交換機支持PCIe分叉,一個PCIe多SSD轉接卡支持每個抽屜超過16個M.2 NAND閃存SSD。

圖5.使用現成組件實現的BaM原型

表3.不同類型 SSD 與 DRAM DIMM 的比較
SSD 技術的折中:表III列出了對三種類型的現成 SSD的BaM系統的設計、成本和效率有顯着影響的指標。RD IOPS (512B, 4KB) 和 WR IOPS (512B, 4KB) 列分別顯示了在512B 和4K粒度下測量的每種SSD的隨機讀寫吞吐量。$/GB 列顯示了每種 SSD 類型的每 GB 成本,基於為構建系統的每個設備、擴展機箱和轉接卡當前的當前報價。Latency 列顯示測量的平均設備延遲(以 µs 為單位)。對 SSD 類型的這些指標進行比較表明,消費級 NAND 閃存 SSD 價格便宜,具有更具挑戰性的特性,而低延遲驅動器(如 Intel Optane SSD 和 Samsung Z- NAND更昂貴,具有更理想的特性。例如,對於使用 BaM 的寫入密集型應用程序,Intel Optane驅動器提供最佳的寫入 IOP 和耐久性。
不考慮底層 SSD 技術,如表 III 所示,BaM和DRAM-only解決方案先比在每GB成本方面有4.4-21.8倍的優勢,即使在使用擴展機箱和轉接板的情況下。此外,這一優勢隨着每台設備增加的額外容量而增長,這使得 BaM 在SSD容量和應用程序數據大小的增加的情況下具有高度可擴展性。
評 估
這個部分進行了對BaM原型軟硬件系統的評估並且展示了:
BaM 可以生成足夠的 I/O 請求以使底層存儲系統飽和(詳見IV-A)。
即使僅有一個SSD,BaM的性能也可以達到活超越最優秀的解決方案(詳見IV-B和IV-C)。
BaM 設計與所使用的 SSD 存儲介質無關,可實現特定於應用的經濟高效的解決方案。
BaM 顯着降低了數據分析工作負載的I/O擴大和CPU控制開銷(詳見IV-C)。
BaM 性能隨着 SSD 的添加而擴展。
綜上,我們展示了和最優秀的解決方案相比,帶有4個Optane SSD的BaM在BFS和CC圖分析數據負載上達到了平均0.92倍和1.72倍的加速性能,並且單個Optane SSD在數據分析負載上達到了4.9倍的加速性能。在不同的存儲媒介上觀察到了和SSD類似的性能。
A.使用微基準測量的BaM的原始吞吐量
設置:我們首先評估了BaM在使用Intel Optane SSD的合成隨機訪問微基準上可實現的原始吞吐量。我們把整個SSD的容量映射到III中描述的GPU的地址空間。我們分配所有的可用的SSD的SQ/CQ隊列對到GPU的內存中,隊列深度為1024。我們之後啟動一個CUDA內核,它的每個線程都從SSD中請求一個獨立的512字節的塊。每個線程提交一個NVMe請求到一個指定的隊列中。隊列以循環方式供給GPU線程使用。然後,我們改變映射到單個 NVIDIA A100 GPU 的線程和 SSD 的數量。對於多個 SSD,請求以循環方式進一步分佈在 SSD 之間。我們將每秒 I/O 操作 (IOP) 衡量為一個指標,該指標定義為GPU提交的請求和內核執行時間。
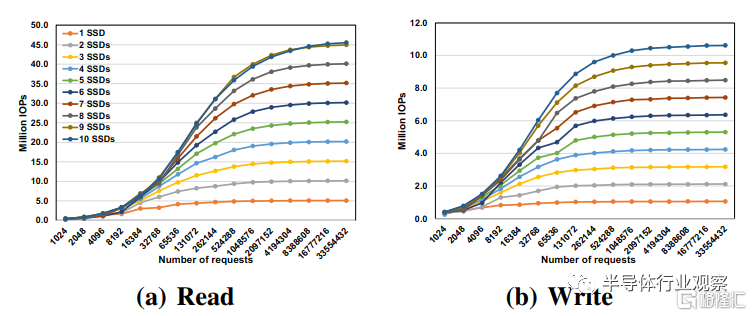
圖6.在 Intel Optane P5800X SSD 上使用 BaM 進行 512B 隨機讀寫基準擴展。BaM 的 I/O 堆棧可以達到每個 SSD 的峯值 IOP,並針對隨機讀取和寫入訪問進行線性擴展
結果:圖 6 顯示了 512B 隨機讀寫訪問基準的測量 IOP,BaM的每個SSD可以達到IOPs的峯值並且可以根據附加的SSD線性增加,對於讀和寫都適用。使用單個Optane SSD,BaM僅僅需要大約16K-64K的GPU線程來達到接近峯值的IOP。使用7個Optane SSD,BaM能達到35M隨機的讀IOP和7.4M的隨機寫IOP,是Intel Optane SSD的512B訪問粒度可達到的最大峯值。擴容實驗中SSD的最大數量目前受限於擴展機箱的抽屜容量。一旦我們完成抽屜級聯的開發,可以進行額外的擴容。相似的性能和擴展性可以在Samsung SSD中看到,並且也可以使用4KB的訪問大小,但是限於篇幅並沒有在此處列出。這些結果驗證了 BaM 的基礎架構軟件可以匹配底層存儲系統的峯值性能。我們下一步會使用應用程序基準來對BaM進行評估。
B.圖分析中的性能收益
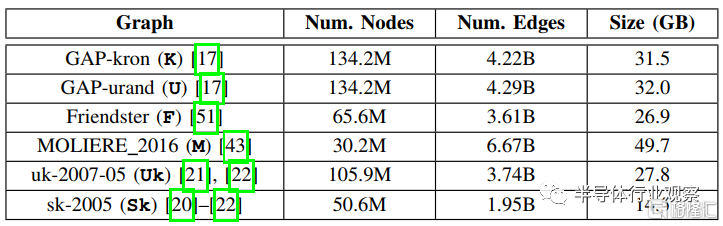
表4.圖分析數據集
設置:首先,我們評估BaM在圖分析應用中的性能收益。我們使用表4列出的圖來進行評估。K,U,F,M是SuiteSparse 矩陣集合中四個最大的圖,而 UK 和 Sk 取自 LAW。這些圖數據集涵蓋了不同的領域,包括社交網絡、網絡爬蟲、生物醫學,甚至合成圖。
BaM的一個目標就是提供比DRAM-only圖分析解決方案更有競爭力的性能。為此,目標基線系統 T 允許 GPU 線程在圖形分析執行期間直接對存儲在主機內存中的數據執行合併細粒度訪問。由於輸入圖都可以放入主機內存中,因此我們可以直接比較 BaM 和 T 之間的性能。
我們在目標系統和構建於表3中列出的不同SSD上的BaM分別運行兩種圖分析算法,廣度優先搜索 (BFS) 和連接組件 (CC)。在 BFS 中,每個 GPU warp 被分配給當前迭代中正在訪問的節點,其中 warp 中的所有線程協作遍歷節點的鄰居列表。CC 實現遵循與 BFS 類似的分配,只是應用程序首先檢查圖中的所有節點,因此呈現出比 BFS 更突發的訪問模式。對於 BFS,我們統計了運行至少 32 個具有兩個以上鄰居的源節點後的平均運行時間。
我們不對 UK 和 Sk 數據集執行 CC,因為 CC 僅在無向圖上運行。最後,我們將 BaM 軟件緩存大小固定為 8GB,緩存行大小為 4KB。

圖7.使用單個Intel Optane SSD 的 BaM 和目標系統(T)的圖形分析性能。平均而言,BaM 的端到端時間比目標快 1.1 倍(BFS)和 1.29 倍(CC)。
一個SSD的整體性能:圖7個展示了目標系統(T)和使用單個Intel Optane SSD的BaM(B_I),Samsaung DC 1735(B_S)和消費級的Samsung grade 980 Pro SSD(B_SC)。回想一下,目標系統 T 受益於主機和 GPU 之間的完整 ×16 Gen4 PCIe 帶寬,而 BaM 僅限於單個 SSD 的 ×4 Gen4 PCIe 接口。
然而,在所有圖和算法中,在不考慮 T 系統的初始文件加載時間的情況下,採用英特爾傲騰 SSD (B_I) 的 BaM 的性能從略快到比目標 T 系統慢 4.4 倍的現象都存在。這是因為由於只有一個SSD,BaM的性能被SSD的x4 Gen4 PCIe接口的吞吐量限制。如果我們考慮T系統的初始文件加載時間,BaM平均比T系統在BFS和CC這兩個算法上分別要快1.1和1.29倍。在這兩種情況下,GPU 計算內核通過 BaM 1D 數組抽象執行按需圖的邊數據訪問。這允許 BaM 將來自 SSD 的某些線程的數據傳輸與其他線程的計算重疊。相反,目標系統 T 需要等到文件加載到內存中才能將計算任務卸載到 GPU。T系統的監管者的主存帶寬不能克服加載初始文件的延遲。這會導致BaM獲得了更高的端對端延遲。
Samsung DC 1735和Intel Optane SSD對於所有的負載幾乎有着相同的新能。因為這兩個驅動器的4KB隨機讀IOP峯值都被PCIe x4 接口限制了。然而對於CC工作負載中的兩個數據集(U和M),Sansung DC 1735的性能比較差,並且我們初始的分析指出了這是因為SSD控制器在處理CC使用突發隨機訪問模板訪問這兩個圖時的長尾部延遲。將重點轉移到成本效益上,BaM 原型使用一個三星 980 Pro SSD,與目標系統(包括文件加載時間)相比,BFS和CC工作負載平均慢1.97倍和1.85倍。這些對於消費級 SSD 來説是非常令人鼓舞的結果,因為它們提供了迄今為止所有 SSD 技術中的最佳價值。
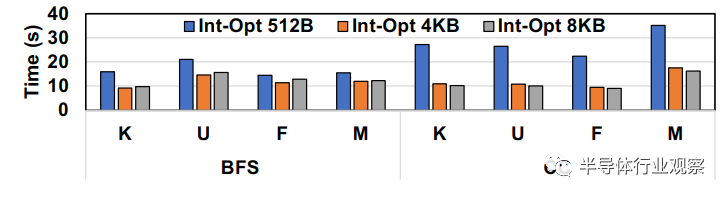
圖8.緩存行大小對使用一塊Intel Optane SSD 進行圖形分析的 BaM 性能的影響
緩存行大小的重要性:我們嘗試調整 BaM 軟件緩存的緩存行大小從 512B 到 8KB,以瞭解訪問粒度對圖形分析工作負載的影響。回想一下,BaM 緩存行大小決定了對存儲的訪問粒度。由於其高IOP率因此使用單個 Intel Optane SSD 完成了評估(詳見表 III)。從圖8中可以看到,由於我們把緩存行大小從4KB減少到512B,BFS和CC工作負載分別慢了1.41倍和2.31倍。這是因為圖工作負載在其鄰接列表中表現出空間局部性,並且可以從更大的訪問中受益。此外,我們的分析數據顯示,對於512B訪問粒度,BFS 和 CC 應用程序可以達到 4.76M IOPs 和 4.97M IOPs。對於4KB訪問粒度,分別可以達到 1.37M IOPs 和 1.52M IOPs。這意味着 512B 和 4KB 存儲訪問的帶寬約為 2.5GBps 和 6GBps,接近一個 Optane SSD 的峯值可實現帶寬。
出現了三個主要發現:
在 BaM 中運行的工作負載可以生成足夠的 I/O 請求以使驅動器的吞吐量飽和.
4K 的粒度在某些圖中利用了大型鄰接列表的空間局部性,並且為較小的鄰接列表傳輸的額外字節不會降低性能,因為 PCIe 帶寬沒有過飽和。
BaM 的細粒度訪問減少了 I/O 放大,從而提高了有效帶寬。
否則,在將緩存行大小從 4KB 減少到 512B 時,應用程序的速度會降低 8 倍。將緩存行大小從 4KB 增加到 8KB 幾乎不會影響整體性能。這是因為在 4KB 時,應用程序接近 SSD PCIe 帶寬限制,並且進一步增加緩存行大小不會提高帶寬。在Samsung設備中觀察到類似的性能變化和趨勢,限於篇幅不討論。
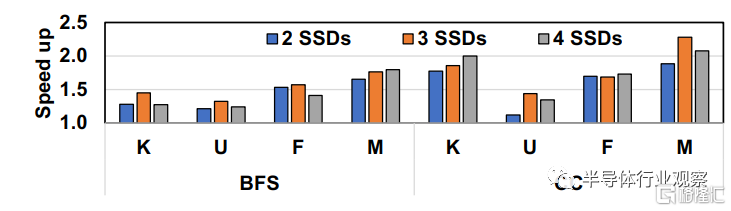
圖9.擴展Optane SSD的數量
擴展到多個SSD:我們擴展 SSD 的數量並跨 SSD 複製數據以增加 BaM 的聚合帶寬。圖9展示了具有4KB緩存行的Optane SSD的擴展結果。使用 BaM 原型的圖形分析工作負載可以很好地擴展到兩個 Optane SSD,但若數量超過兩個,收益開始遞減。如果使用超過兩個SSD,使用BaM原型的圖分析應用就不能以足夠的速度產生I/O請求來有效地滿足附加設備。即使應用程序具有足夠的 I/O 並行度,當前的 GPU 內核實現和數據佈局都針對利用局部性和減少 I/O 請求的數量進行了優化,而不是最大化生成 I/O 請求的速率以隱藏長延遲。這些相互衝突的目標需要通過掃描每個線程的工作分配或增加每個線程的工作量來探索設計空間,以便 GPU 線程可以以更高的速率生成 I/O 請求以充分利用超過 2 個 Optane SSD。此外,BaM 軟件棧中的一些優化,例如自動改變 I/O 請求的大小和預取,尚未實現。我們將在未來解決這些問題。目前,使用四個Intel Optane SSD的系統和考慮文件加載時間的目標系統T相比已經可以在BFS和CC應用上提供平均0.92和1.72倍的加速比。BaM在所有數據集上對於BFS和CC負載達到了平均0.72 和1.51倍的加速比。三星 SSD 也出現了類似的趨勢,但三星 980 Pro SSD 可以很好地擴展到 4-10 個 SSD,然後再擴展SSD才會在圖形工作負載上出現收益遞減。
C.數據分析中的I/O擴大收益
除了圖形分析之外,我們還評估了 BaM 原型對企業數據分析工作負載的性能優勢。這些新興的數據分析被廣泛用於解釋、發現或推薦隨時間推移或從非結構化數據湖收集的數據中的有意義的模式。數據分析實驗旨在説明 BaM 設計在處理大型結構化數據集時減少 I/O 擴大和軟件開銷的好處。
設置:II-B中討論了在NYC出租車數據集上的I/O擴大問題。該數據集由 200GB 編碼數據組成,以優化行列 (ORC) 格式組織為 1.7B 行和 49 列。我們使用了II-B部分中描述的6個數據相關的提問來和最優秀的GPU加速數據分析框架RAPIDS進行比較。基線和BaM都使用一塊Intel Optane P5800X SSD。我們使用兩種配置來評估基線:a)SSD 中所有數據的冷情況和 b)數據已被提取到 Linux CPU 頁面緩存的暖情況。

圖10.使用一個 Optane SSD的前提下,在NYC出租車數據集的數據分析查詢中BaM 和 RAPIDS 的性能。BaM 比以 CPU 為中心的 RAPIDS 框架快 4.9 倍。
結果:在大多數情況下,採用單個英特爾傲騰 SSD 的 BaM 在冷配置和暖配置中均優於 RAPIDS 性能,如圖 10 所示。對於 Q1,暖配置的基線比 BaM 略有優勢,因為它可以利用整個 CPU DRAM 帶寬和 PCIe ×16 Gen4 帶寬在主機和 GPU 之間傳輸數據,而 BaM 則受到 SSD 帶寬的限制。隨着數據相關指標的添加,BaM 性能提高,如圖 10 所示。性能提高的原因是 BaM 由於按需數據提取而減少了 I/O 放大,但基線必須將整個列傳輸到 GPU 內存。如圖 2 所示,通過額外的數據相關指標,基線(包括暖和冷)會引起更多的I/O擴大和CPU上用於查找和移動數據以及管理GPU內存的軟件開銷。但是,BaM 能夠按需訪問數據以及重疊計算、緩存管理和許多 I/O 請求,這使得它處理多個數據相關列的效率幾乎與處理單個數據相關列一樣高。
相關工作
A.優化的以CPU為中心的模型
大多數 GPU 編程模型和應用程序的設計都假設工作數據集適合 GPU 內存。如果沒有,則使用平鋪等特定於應用程序的技術來處理 GPU 上的大數據。
SPIN和 NVME建議使用 GPUDirect RDMA 從SSD到GPU 啟用對等 (P2P) 的直接內存訪問,這樣就可以不在數據通路中使用CPU。SPIN 將 P2P 集成到標準 OS 文件堆棧中,併為順序讀取啟用頁面緩存和預讀方案。GAIA進一步將 SPIN 的頁面緩存從 CPU 擴展到 GPU 內存。Gullfoss提供了一個高級接口,有助於高效地設置和使用 GPUDirect API。Hippogriffdb為 OLAP 數據庫系統提供 P2P 數據傳輸功能。GPUDirect Storage是使用 GPUDirect RDMA 技術在 NVIDIA CUDA 軟件棧中將數據路徑從 CPU 遷移到 GPU 的最新產品。在 RADEON-SSG 產品線中可以看到 AMD 的類似努力。所有這些工作仍然採用以 CPU 為中心的模型,其中 CPU 負責數據傳輸控制。BaM 提供從 GPU 對存儲的顯式和直接細粒度訪問,允許 GPU 中的任何線程啟動、讀取和寫入數據到 SSD。
B.以加速器為中心的模型的先前嘗試
ActivePointers、GPUfs、GPUNet 和 Syscalls for GPU之前曾嘗試啟用以加速器為中心的數據編排模型。GPUfs和Syscalls for GPU首先允許GPU從主機CPU請求文件數據。ActivePointers在GPUfs之上添加了類似抽象的內存映射,以允許GPU線程像數組一樣訪問文件數據。Dragon建議將存儲訪問納入UVM頁面錯誤機制。然而,所有這些方法都依賴於並行性明顯較低的CPU來處理大規模並行GPU的數據需求。因此,如II部分中所示,這些方法最終導致資源利用不足和整體性能不佳。此外,所有這些工作都沒有利用GPUDirect RDMA功能,而是依賴於先將數據傳輸到CPU內存,然後再傳輸到GPU內存的工作方式。
C.硬件擴展
通過直接用閃存替換全局內存或將其與GPU內存系統緊密集成來擴展對GPU的非易失性內存的支持方案已經被提出。DCS建議藉助專用硬件單元(如 FPGA)實現存儲、網絡和加速器之間的直接訪問,為粗粒度數據傳輸提供所需的轉換。最近有人提出在GPU內啟用持久化。我們承認這些努力,並進一步驗證了為新興工作負載啟用大內存容量的必要性。更重要的是,BaM旨在使用現有的硬件和系統在具有非常大的真實數據集的端到端應用程序中提供光速性能。
結論
在這項工作中,我們提出了一個案例,使 GPU 能夠在稱為 BaM 的新系統架構中協調對 NVMe 固態驅動器 (SSD) 的高吞吐量、細粒度訪問。BaM 通過按需讀取或寫入更精細的粒度(由這些 GPU 上運行的計算代碼決定)來緩解讀取比所需數據更多的數據的 I/O 放大問題。使用現成的硬件組件,我們使用不同的 SSD 類型實現 BaM 原型,並在多個應用程序和數據集上進行了測試,結果表明 BaM 是DRAM-only和其他以 CPU 為中心的最優秀解決方案的可行替代方案。


More Content