本文來自格隆匯專欄:錦緞 作者:俊宏
最近一個週期,我國在前沿硬科技領域投入越來越大,相關論文發表和論文引用量逐漸開始佔領世界第一的位置。數量上的進步鼓舞人心,但質量上的全面突圍還需要耐心。
比如GPU(圖形處理器)。
某種意義上,它當前是通往AI世界那道命門:由於AI算法屬於計算密集型算法,海量的數據處理任務和人工智能的訓練和推理更適合GPU、FPGA、ASIC等並行計算能力強的芯片。
眾所周知的是,這些先進芯片的生產和製造基本都被把握在海外廠商手上。
故而對於中國科技產業來説,自建GPU等核心AI底層硬件,是一件既刻不容緩又需要極大耐心的工程。
自2017年以來,多箇中國新一代初創型GPU研發公司相繼成立,正逐漸走上歷史舞台。而作為二級市場中獨一份的國產標的,A股GPU 第一股的景嘉微(SZ:300474),也憑藉股價的年內翻倍走勢而愈加受到關注。
本文作為我們聚集中國GPU產業的系列研究開篇,將以景嘉微為線索,在探究其虛實同時,力求延伸出更多的產業維度思考。
01
烏龍研報
2016年,GPU業界誕生了一塊被戲稱“老黃手抖切多了”的神卡:GTX1080。
這塊顯卡是英偉達(NASDAQ:NVDA)在新架構(Pascal)上的第一個作品,作為首發先鋒,秒掉了上一代架構(Maxwell)的所有卡。該卡在314mm²的核心面積裏面塞進去了72億晶體管。時至今日,GTX1080都能被稱之為是一塊高性能卡,能夠滿足絕大部分遊戲需求。
不過根據某券商在9月17日的一份報吿中提到,景嘉微擁有完全自主知識產權的的JM9系列GPU流片成功了,“產品性能與GTX1080相當”。如果該產品性能真的如研報所示,那麼該產品一旦量產成功可直接改寫中低端GPU國內市場勢力格局。
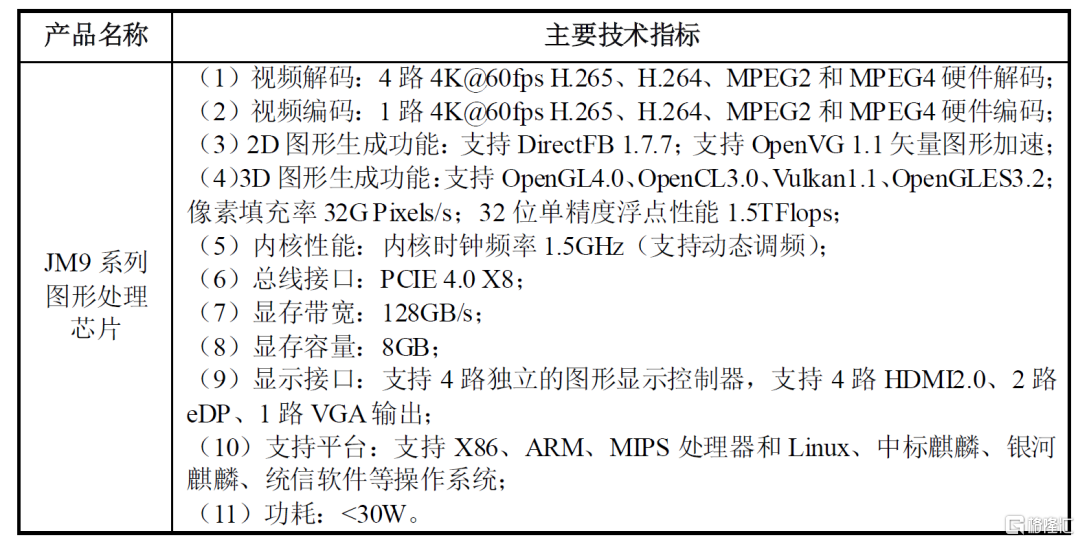
圖片來源:公司公吿
上圖是公司目前公佈的技術指標。可以看到的是,理想很美好,現實仍骨感:
視頻解碼方面能夠達到目前的主流水平,支持4K60支持H265,已經足夠日常看視頻使用了。3D圖形支持OpenGL 4.0,目前最新的OpenGL是4.6,也算是跟上前沿步伐。
最後是支持的平台,支持X86和ARM,這意味着可以支持x86下的linux操作系統。這使中標麒麟、UOS、銀河麒麟等國產操作系統的支持就有了可能。
但,在算力層面,JM9系列跟GTX1080還不在一個級別。

像素填充率表示的是GPU每秒能夠渲染填充進畫面的像素數量。單精度浮點性能是GPU每秒能完成計算的數量。簡單來説這兩個指標都能表達GPU的算力情況。如果説從數據推算上能打贏GTX1080的話,唯一能比的就是功耗算力比。
可問題在於,脱離了絕對性能和架構PK功耗算力比,完全是關公戰秦瓊了。按這個説法,高通驍龍888功耗10W,但其所集成的GPU算力在1.7TFlops,比景嘉微JM9還要高一截。於是把驍龍888裝進PC裏就能比GTX1080更強大麼?恐怕不是這麼比的。
出現這種説法應該是研究員在數據比對中出現了什麼誤會。
 圖:相關券商研報
圖:相關券商研報
從使用場景來説JM9 系列圖形處理芯片產品可滿足地理信息系統、媒體處理、CAD 輔助設計、遊戲、虛擬化等高性能顯示需求和人工智能計算需求。
對於前面的專業需求來説,景嘉微作為國產自主設計GPU廠商在政採和軍供方面是必須要滿足的。在遊戲和虛擬化層面,由於JM9支持Linux內核的操作系統,這樣的性能還是能夠玩一些“老遊戲”的。但是支持人工智能計算又是從何説起呢?
02
AI命門
CPU(中央處理器)和GPU(圖像處理器)在設計目標上都是為了完成計算的用途。兩者的區別在於芯片內部的設計結構差異。CPU擅長完成較難和較長的任務,而GPU憑藉多運算核心可以同時執行多個較為簡單的任務。
例如在把不同像素填充進圖形的渲染任務中,CPU的執行方式是分別計算出每一個像素的具體顏色再填充進圖形。而GPU可以憑藉核心數量多的優勢同時計算全部的像素顏色,再同時填充進圖形。雖然CPU可以憑藉足夠快的計算速度來完成這一工作,但小汽車就算開得再快也難於與大貨車的運貨能力相抗衡。

圖片綠色區域是運算核心,來源:NVIDIACUDA技術文檔
人工智能中使用的機器學習模型是通過模擬生物神經系統來建立的數學網絡模型,需要大量數據來訓練模型,對計算機處理器的要求是需要大量並行計算。這就要求芯片能夠提供多核並行計算能力,核心數量多,擁有更高的浮點運算能力和訪存速度的能力,以此來提升深度神經網絡的訓練速度。
在當前AI應用中,計算芯片在神經網絡訓練中需要解決兩個限制。第一是芯片內部到外部的帶寬以及片上緩存空間對運算的限制。第二是在控制功耗的同時不斷提升專用計算能力,解決對卷積、殘差網絡等各類AI計算模型的大量計算。雖然在今天能夠滿足上述兩種需求的芯片主要是GPU、ASIC、FPGA,但這三者同時也具有不同的優缺點。

當前AI發展還處在一個相對早期的階段,應用層面分化仍不明顯。例如在挖礦工作中,需要計算芯片連續不斷執行同一種簡單邏輯操作,ASIC作為最快速的芯片就比較適合。在通信行業中,針對接受不同信號並轉碼的任務交給單一軟件邏輯的FPGA是當前主要的研究方向。
但在機器視覺、自動駕駛方面,由於算法更迭快,不能支持ASIC每次特定設計的生產成本。同理,FPGA不能支持神經網絡的邏輯遞歸處理。中長期來看,GPU得益於通用性和製程仍有進步空間的優勢,仍然是主流AI研究和開發平台。甚至可以説,AI行不行,得先在GPU上跑通了再説。
在未來,通過AI處理或輔助的方式能夠大大優化生產過程和提高生活質量。對AI科技公司來説,擁有更多開發人員和更多前言研究論文固然重要。但在沒有或受限的硬件條件下進行AI研究,無疑是空中樓閣。
國產自有GPU補充前沿科技研究的需求,呼之欲出。
03
引申思考
高新科技的研究和進步遠遠不是單一領域突破就能實現的,一味追求追高追新的心態有可能會重蹈2003年的“漢芯事件“。
在自研GPU的研發領域上,我們應該關注不應該是誰的產品最有噱頭,更應該看的是誰的核心技術最全面,誰能持續穩健的完成技術飛躍。回到景嘉微的JM9系列,深入研究發現這家公司不簡單,可能是未來國產GPU領軍龍頭。
景嘉微成立於2006年,公司產品主要分為圖形圖像處理系統、小型雷達系統、GPU芯片,廣泛應用於軍工行業。公司圖形顯控領域產品包括圖顯模塊和加固類產品,其中圖顯模塊是核心產品。
景嘉微成立當年,恰逢我國軍用飛機圖形顯控系統由使用DSP與FPGA圖形加速器向使用GPU圖形處理器升級,公司準確把握機遇,將大量資源投入飛機圖形顯控領域的研究。
在當時國內外主要採用的是ATI的M9芯片,景嘉微研發VxWorks嵌入式操作系統下M9芯片驅動程序,並於2007年研發成功。雖然芯片驅動距離芯片製造還差了十萬八千里,但有自己的驅動來控制芯片,這仍算得上是打響我國圖形顯控模塊擺脱外商依賴第一槍。
2014年,第一代圖形處理芯片(GPU)JM5400研製成功,性能優於軍工電子顯控領域主流進口芯片。2018年,第二代圖形處理芯片(GPU)JM7200研製成功,在第一代基礎上有較大進步。目前JM5400系列已應用於多種軍用顯控系統中,JM7200已獲得軍工意向訂單。
從這一代開始,景嘉微基本包攬了全部軍用領域的圖顯和顯控訂單。順着這代性能的提升,做了芯片與國產CPU的適配,推出了JM7201希望進入到民用市場。這塊JM7201的性能應今天的眼光來看,相當於是以獨立顯卡達到了彼時搭載在國外主板上的集成顯卡的水平。
那麼如今發佈的JM9系顯卡究竟是什麼水平?直白來説,以這個公佈的數據來看,JM9系列相當於80%參數水平的GTX950。而GTX950是在2015年中高端顯卡。
但是,作為一款自主知識產權顯卡,其對功耗的控制和惡劣環境的魯棒性這點是毋庸置疑值得誇讚的。在目前公開版本後續會不會有“加料“的商用版出現也是極有可能的。從參數來説,JM9已經能夠完美的解決辦公需求,未來在ToG的增量可以期望。
在最後,想説幾句題外話。高科技的研發過程是漫長的,只靠授權開發和承他人之蔭是不能突破技術封鎖的。對任何一家處於成長中的科技硬件公司,重要的不是現在有什麼,而是其產品的必要性和願意研發並持續進步的決心。對於現實產品,不能專業指出缺點反而無腦吹捧不會有裨益,反而會引起不明情況消費者的疑惑。
在未來,科技上的博弈還會持續相當久的時間。前沿技術的發展我們不能停滯,提供這些技術誕生的載體(國產CPU、GPU、內存等)更是不容懈怠。
畢竟,東西是自己的才是硬道理。


More Content