类比计算机系统的基础软件层以及云计算三层架构的PaaS层级,我们认为,AI产业链中也有层级相似,定位于算力与应用之间的“桥梁”角色的基础软件设施层即AI Infra。新一轮生成式AI浪潮,对于上层应用而言机遇与挑战并存,而AI Infra作为必要的基础设施,我们认为其技术及商业发展前景的确定性或更强。本文我们聚焦AI Infra,揭示其内涵并总结目前国内外项目的商业化进展,再从工作流视角详细梳理各环节及代表厂商。我们认为,AI Infra是AI产业必不可少的基础软件堆栈,“掘金卖铲”逻辑强、商业潜质高,建议投资者持续关注AI Infra相关投资机会。
摘要
在预训练大模型时代,我们可以从应用落地过程里提炼出标准化的工作流,AI Infra的投资机会得以演绎。传统ML时代AI模型通用性较低,项目落地停留在“手工作坊”阶段,流程难以统一规范。而大规模预训练模型统一了“从0到1”的技术路径,具备解决问题的泛化能力,能够赋能“从1到100”的各类应用,并存在相对标准化的工作流,由此衍生出AI Infra投资机会。GPT 4的开发经验也体现专业分工的必要性:根据OpenAI的披露,在GPT 4的开发过程中,其对249人研发团队进行了明确分工,并使用了数据标注、分布式计算框架、实验管理等点工具。我们认为这也说明了在大模型时代应用基础软件的必要性。目前,AI Infra产业处于高速增长的发展早期,我们预计未来3-5年内各细分赛道空间或保持30%+的高速增长,且各方向均有变现实践与养成独角兽企业的潜力。
“AI = Data + Code”,组织AI所需的养料即数据,管理AI模型的训练部署过程,以及支持从模型到应用的整合是AI Infra工具的关键能力。1)数据准备:无论是支持经典的机器学习模型还是大规模预训练模型,数据准备都是耗时较久、较为关键的一环。我们认为,LLM浪潮下高质量的标注数据和特征库需求将持续增长,未来海量训练数据的需求或由合成数据满足。此外,我们强调Data+AI平台厂商的关键卡位。2)模型训练:预训练模型的获取使得模型库更加流行,LLM大规模训练需求也驱动底层分布式计算引擎和训练框架的迭代。此外,我们认为实验管理工具重要性较高。3)模型部署:LLM模型端的突破释放出大规模应用落地的潜能,更多模型从实验走向生产环境,我们认为有望整体提振模型部署和监控的需求。4)应用整合:LLM赋能应用催生对向量数据库和应用编排工具等的新需求。我们观察到经典的机器学习时代与大模型时代工具栈需求侧重点有所不同,同时,部分点工具正在拓宽产品功能边界,LLMOps平台型产品的可及市场空间天花板或更高。
风险
技术进展不及预期、应用落地不及预期、行业竞争加剧。
图表1:一图详解大模型时代的基础软件堆栈——AI Infra

注:图中市场规模数据为我们在正文图表9相关资料来源基础上估算得到的约数;图中灰色文本框为我们的观点 资料来源:Grand View Research,Foresight News,Gartner,MarketsandMarkets,拾象科技,Firstmark,a16z,各公司官网,中金公司研究部
初见:AI Infra是连接算力和应用的AI中间层基础设施
本章主要讨论:1)AI Infra在AI时代IT生态中的定位;2)为什么大模型浪潮下需要格外关注AI Infra投资机会;3)AI Infra基础软件工具栈涵盖内容;4)AI Infra商业化初探。
类比基础软件和PaaS,AI Infra是AI时代的中间层基础设施
从类比的角度理解AI Infra:AI时代连接硬件和上层应用的中间层基础设施。传统本地部署时代,三大基础软件(数据库、操作系统、中间件)实现控制硬件交互、存储管理数据、网络通信调度等共性功能,抽象并隔绝底层硬件系统的复杂性,让上层应用开发者能够专注于业务逻辑和应用功能本身的创新实现。云时代同理,形成了IaaS、PaaS、SaaS三层架构,其中PaaS层提供应用开发环境和基础的数据分析管理服务。类比来看,我们认为,进入AI时代也有承担类似功能的、连接算力和应用的基础设施中间层即AI Infra,提供基础模型服务、赋能模型微调和应用开发。
图表2:AI Infra是人工智能时代连接硬件和上层应用的中间层基础设施

资料来源:中金公司研究部
大模型通用性赋能下应用落地流程更加标准化,催生AI Infra投资机会
LLM流行前,AI模型通用性较低,项目落地停留在“手工作坊”阶段,流程难以统一规范。人工智能已有数十年的发展历史,尤其是2006年以来以深度学习为代表的训练方法的成熟推动第三波发展浪潮。然而,由于传统的机器学习模型没有泛化能力,大部分AI应用落地以定制化项目的形式,包括需求、数据、算法设计、训练评估、部署和运维等阶段,其中,数据和训练评估阶段往往需要多次循环,较难形成一套标准化的端到端的流程和解决方案,也由此造成了边际成本高、重复造轮子等问题。
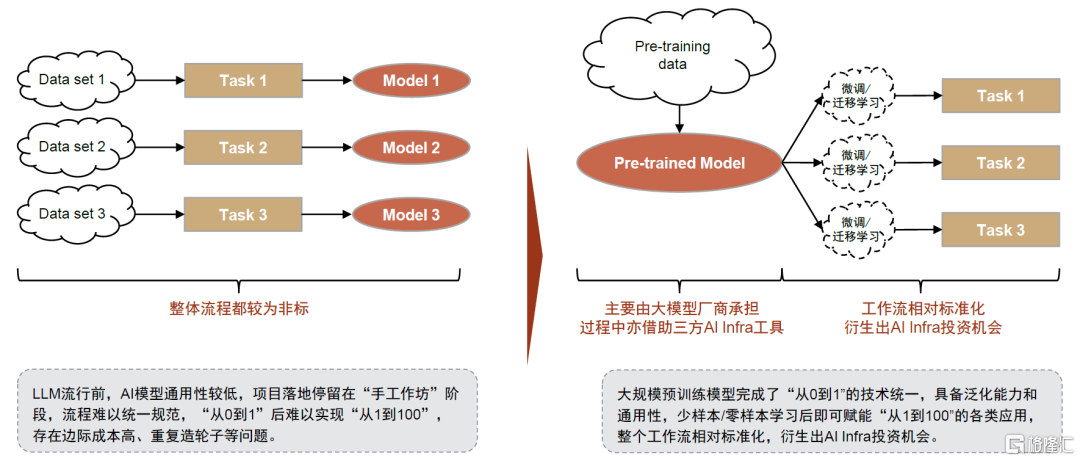
大规模预训练模型完成了“从0到1”的技术统一,泛化能力和通用性释放出“从1到100”的落地需求,且存在相对标准化的流程,衍生出AI Infra投资机会。基于Transformer算法、超大参数量的预训练模型拥有泛化能力,一定程度上解决了原先需要按项目定制训练的问题,过去正因为ML模型的非标和项目制,下游需求并未被完全激发出来,LLM模型端的突破释放出更大规模的应用落地潜能。而后续的应用过程中主要涉及:高质量样本数据的准备、基础模型获取、模型微调及部署监控、应用编排开发上线等环节,工作流较为标准化,我们建议投资者持续关注AI Infra投资机会。
图表3:具有泛化能力的通用大规模预训练模型赋能下,后续工作流较为标准化,衍生出AI Infra投资机会
资料来源:中金公司研究部
从OpenAI实践看分工必要性,核心关注工作流相关的基础软件工具栈
参考海外OpenAI的率先尝试,工作流分工、点工具加持助力成功。一方面,OpenAI在《GPT-4 Technical Report》论文中[1]中披露了参与GPT 4开发的人员分工,共249人,角色分工明确,预训练、强化学习和对齐、部署等6个大方向下又拆分成不同小组,其中数据集/数据基础设施、分布式训练基础设施、推理基础设施等分别对应工作流中的数据准备、模型训练、部署应用等环节;另一方面,OpenAI使用了Scale数据标注服务、Ray分布式计算框架和Weights and Biases(W&B)实验管理工具,且W&B的创立灵感就来自于其创始人之一在OpenAI的实习经历。我们认为,OpenAI的率先尝试经验一定程度上说明专业分工和AI Infra基础软件堆栈在大模型时代的必要性。
图表4:Open AI《GPT-4 Technical Report》中披露的人员分工明确

资料来源:《GPT-4 Technical Report》(OpenAI,2022),中金公司研究部
AI Infra广义上包含了基础模型和基础软件栈两层,本篇报吿核心关注其中和工作流相关的基础软件工具栈。工作流的视角下,LLM的开发应用主要涉及数据准备、模型训练、模型部署、产品整合四个主要环节,每个环节都有对应的点工具,亦有集大成的LLMOps平台型产品,我们将在下一章详细解读。
图表5:AI Infra全景图

资料来源:a16z官网,拾象科技公众号,中金公司研究部
商业化起步中,已有变现实践,细分赛道或均有长出独角兽的潜力
商业化起步阶段,有望在未来几年快速成长为百亿美元量级的产业。我们认为,AI Infra整体处于高速增长的发展早期,如图表9的整理,根据第三方数据,目前大部分细分赛道规模在几亿至几十亿美元量级,我们预计在未来3-5年内或将保持30+%的高速增长。同时,Data+AI、MLOps/LLMOps等平台型产品的市场空间天花板可能更高,我们也观察到点工具厂商正在积极拓展产品边界。我们认为,AI Infra是AI时代不可或缺的基础设施中间层,“掘金卖铲”逻辑的确定性高,有望持续受益于LLM、AI应用的繁荣。
图表6:AI Infra细分赛道市场规模
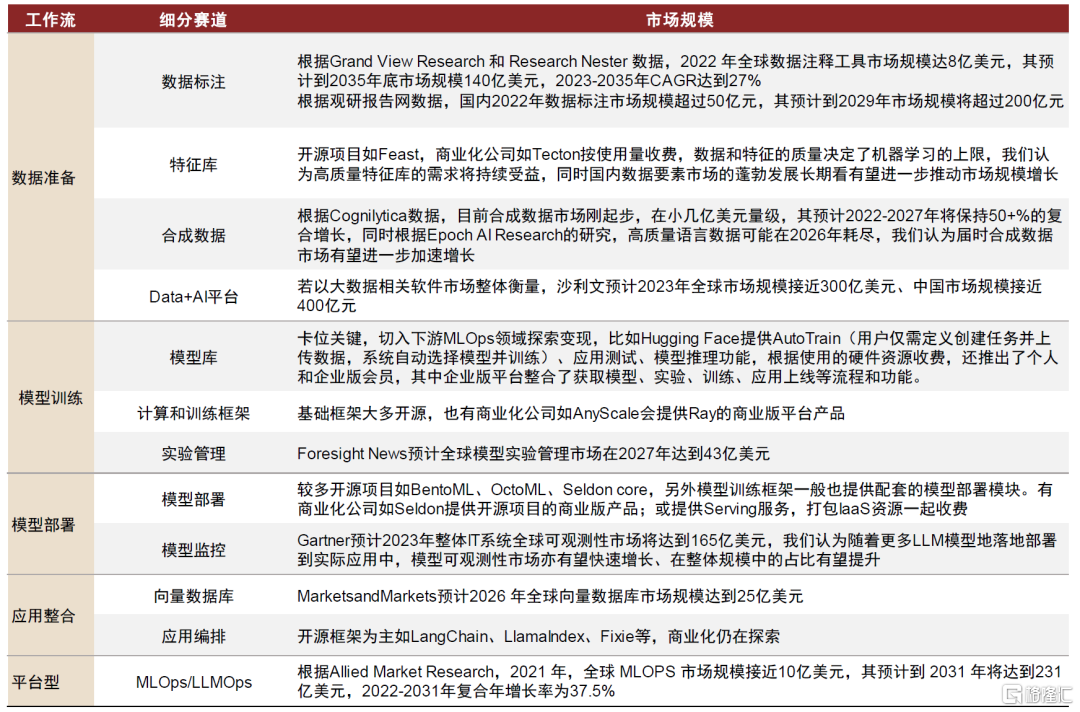
资料来源:Grand View Research,Foresight News,Gartner,MarketsandMarkets,Cognilytica,沙利文,Allied Market Research,Research Nester,中金公司研究部
海外厂商积极探索变现,细分赛道或均有长出独角兽的潜力。从微观的视角,我们整理了AI Infra各细分赛道海外代表公司的商业模式,基本遵循按使用量付费的定价模式。大多数创业公司成立时间较短,详见图表10,目前收入体量在数千万至小几亿美元量级,其中数据相关的、平台型的厂商起步较早、已初具规模,我们认为这也符合数据需要前置于AI模型投入、平台型厂商收入天花板更高的逻辑。此外,我们认为LLM模型端突破将释放出更大规模应用落地的潜能,有望带动模型部署、应用整合等后续环节的逐步起量。
图表7:AI Infra各赛道代表公司的商业模式一览
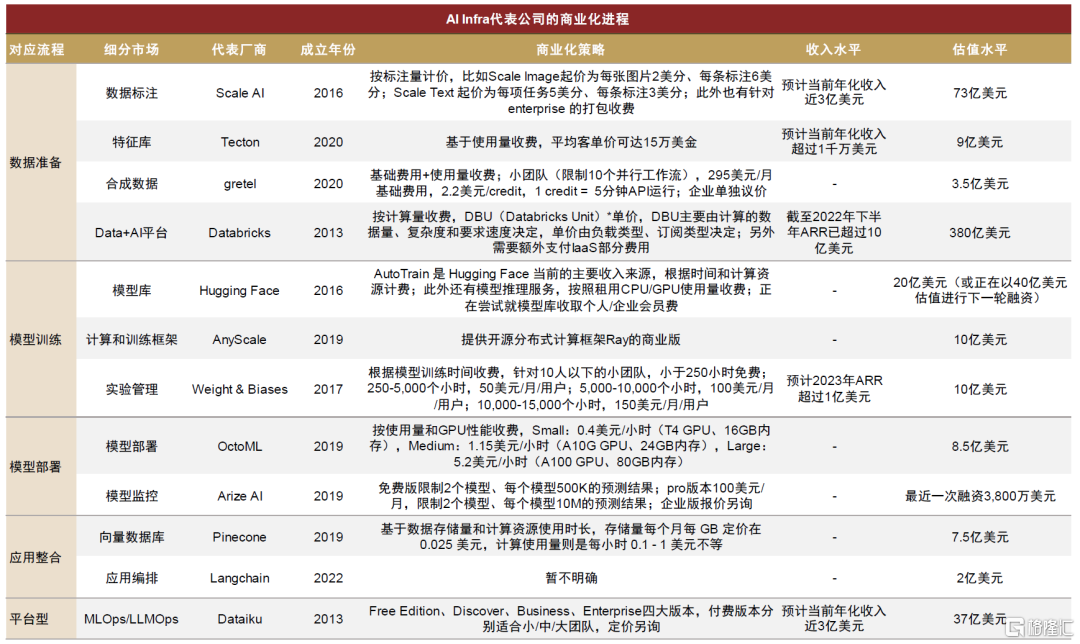
注:估值取最近一次公开融资披露数据,统计截至2023年7月;收入水平中,Scale AI、Tecton、Dataiku为Growjo网站预测,Databricks来自公司官网披露,Weight&Biases为海外独角兽公众号预计 资料来源:各公司官网,海外独角兽公众号,Growjo,中金公司研究部
探秘:从工作流视角梳理AI Infra投资机会
大模型时代和传统机器学习时代工具栈侧重点有所不同
本章从企业训练模型、构建AI赋能应用的工作流视角出发,详解涉及的主要环节,并关注LLMOps和MLOps在流程上的侧重点差异。我们认为AI = Data + Code,历经数据准备、模型训练、模型部署、产品整合,分环节看:
► 数据准备:高质量标注数据、特征库需求持续,合成数据或成未来趋势。数据准备无论在传统的MLOps还是LLMOps中都是耗时较久、较为重要的一环。无监督学习降低对标注数据的需求,但RLHF机制体现了高质量标注数据的重要性,我们认为未来超大参数量模型对海量训练数据的需求或由合成数据满足。此外,Data+AI平台厂商卡位关键。
► 模型训练:模型库更加刚需,训练框架持续迭代,软件工具协助实验管理。基于通用的LLM大模型微调、蒸馏出小模型成为高性价比的落地方式,因此需要能够高效便捷地获取预训练模型的模型库;也催生更适应LLM大规模训练需求的底层分布式计算引擎和训练框架。此外,我们认为实验管理工具的重要性或始终较高。
► 模型部署:更多模型从实验走向真实业务环境,部署和监控需求提升。我们认为,LLM模型端的突破释放出大规模应用落地的潜能,更多的模型从实验环境走向生产环境,有望整体提振模型部署和监控的需求。
► 应用整合:催生向量数据库和应用编排框架新需求。LLM赋能应用催生出对应用产品整合相关工具产品的需求,其中较为关键的是向量数据库和应用编排工具。
图表8:从工作流视角梳理,大模型时代和传统ML时代工具栈侧重点有所不同
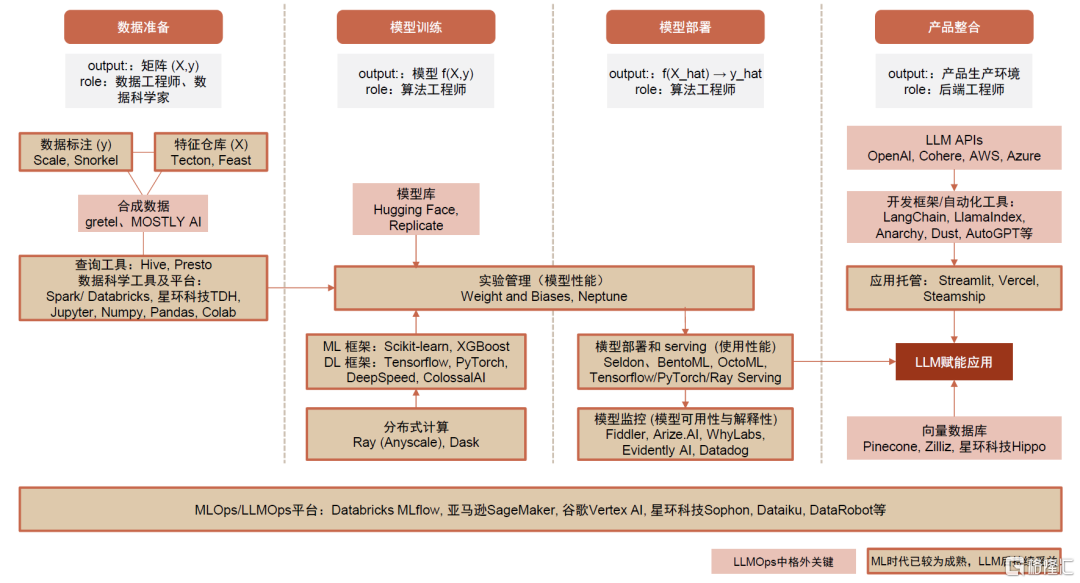
资料来源:拾象科技,Firstmark,a16z官网,中金公司研究部
数据准备:高质量标注数据、特征库需求持续,合成数据或成未来趋势
数据是模型的起点,一定程度上决定了模型的效果和质量,数据准备无论在传统的MLOps还是LLMOps中都是耗时较久、较为重要的一环。LLM带来的新变化主要包括:1)虽然LLM的无监督学习机制降低了对标注数据的需求,但OpenAI的RLHF(Reinforcement Learning from Human Feedback)体现了高质量标注数据重要性;2)模型规模大幅提升,带来日益增长的训练数据需求,长期看可能无法仅通过真实世界数据满足,合成数据提供一种AIGC反哺AI的解法。此外,数据基础管理软件平台的卡位始终关键,Data+AI平台化趋势持续演进。
数据标注:GPT的成功说明了高质量标注数据对提升模型效果的重要性。数据标注位于模型开发的最上游,对图像、视频、文本、音频等非结构化原始数据添加标签,为AI提供人类先验知识的输入。近年,无监督学习(事先不定义明确目的)、强化学习(通过奖励函数来指导学习过程)等不需要标注数据的机器学习分支方法论的出现引发市场对于数据标注必要性的讨论与担忧。不过,OpenAI通过RLHF即基于人类反馈的强化学习来优化模型,且从OpenAI[2]披露的分工中能看到有很多负责预训练、强化学习等的AI科学家也参与到数据准备中;最新开源的LLAMA 2的论文[3]中也有一段强调高质量数据对模型训练结果影响的表述,Meta与第三方供应商合作收集了近3万个高质量标注,又向市场证明了高质量数据标注工作的重要性。
图表9:高质量标注数据在GPT模型训练中起重要作用
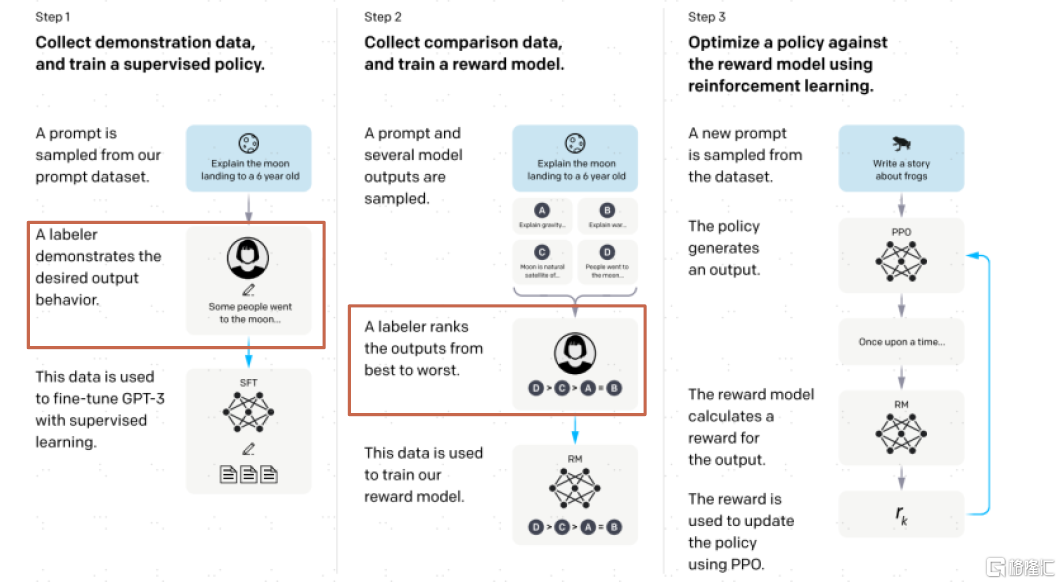
资料来源:《Training language models to follow instructions with human feedback》(OpenAI, 2022),中金公司研究部
数据标注厂商正在寻求智能化转型、减少对人力的依赖。在数据标注助力AI快速发展的同时,AI也将反哺数据标注更加自动化、智能化,如利用模型进行数据预处理再人工审核等。今年4月Meta AI发布的Segment Anything Model[4]的训练数据集SA-1B,就是通过智能数据引擎来辅助自动化生成的,该数据引擎经历了辅助手动标注-半自动标注-自动化标注的训练过程。
特征库(Feature Store):高质量特征库持续受益。特征是预测模型的输入信号,可以简单理解为模型中的自变量X,需要经过特征工程从原始数据中筛选得到。而特征库则是生产、管理、运营ML过程中所需数据及特征的系统,主要实现1)运行各类数据管道(Pipeline)将原始数据转换为特征值;2)存储和管理特征和数据;3)为训练和推理提供一致的特征服务。目前该领域的代表性产品包括:开源项目如Feast,独立商业化公司如Tecton,大型科技厂商的ML平台如Databricks、SageMaker等中亦有相应模块。数据和特征的质量决定了机器学习的上限,我们认为高质量特征库有望持续受益,同时国内数据要素市场的蓬勃发展长期看有望为AI模型供应更多高质量的数据燃料。
图表10:特征库是生产、管理、运营ML过程中所需数据及特征的系统
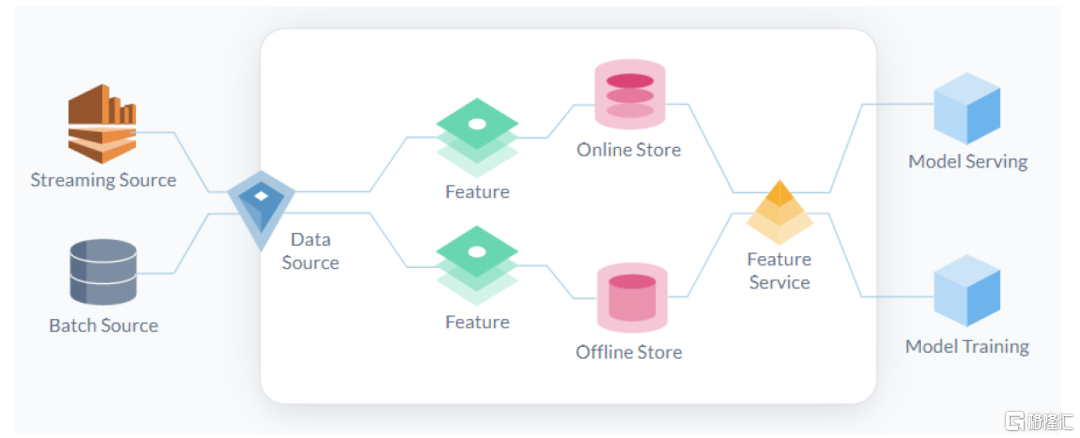
资料来源:Tecton官网产品文档,中金公司研究部
合成数据:做真实数据的“平替”,用AIGC反哺AI。一项来自Epoch AI Research团队的研究预测存量的高质量语言数据将在2026年耗尽[5],低质量的语言和图像数据存量也将在未来的数十年间枯竭。面对潜在的数据瓶颈,合成数据即运用计算机模拟生成的人造数据,提供了一种成本低、具有多样性、规避了潜在隐私安全风险的解决方法,生成式AI的逐渐成熟进一步提供技术支撑。比如,自然语言修改图片的Instruct-Pix2Pix模型在训练的时候就用到GPT3和Stable Diffusion来合成需要的提示词和图像的配对数据集;Amazon也利用合成数据来训练智能助手Alexa[6],以避免用户隐私问题。合成数据市场参与者较多,独立公司/项目如gretel、MOSTLY AI、datagen、hazy等,数据标注厂商如Scale亦推出相关产品,此外主流科技公司英伟达、微软、亚马逊等均有不同场景的尝试。
图表11:Instruct-Pix2Pix借助GPT-3、Stable Diffusion生成指令-图像训练数据集
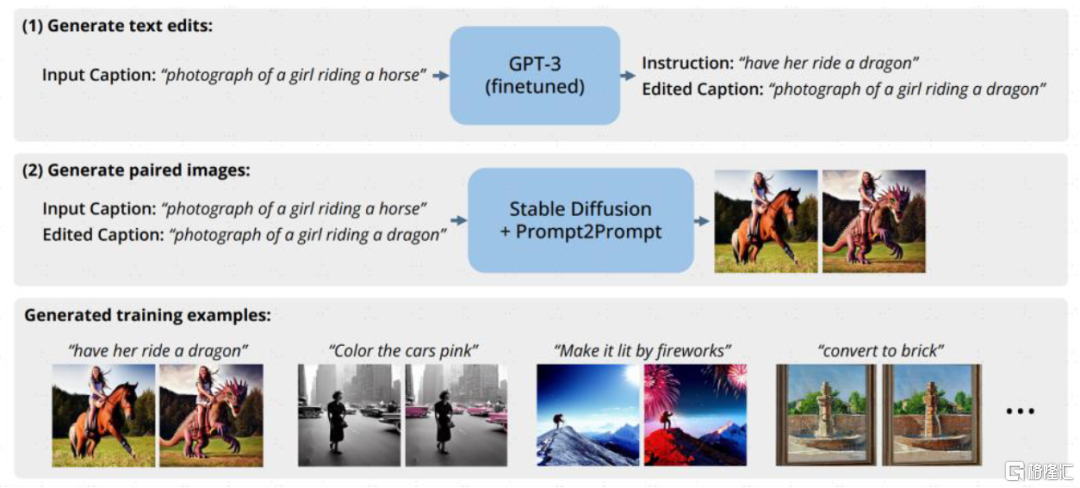
资料来源:《InstructPix2Pix: Learning to Follow Image Editing Instructions(Tim Brooks等,2022》,中金公司研究部
数据科学基础平台:数据卡位始终关键,Data+AI是行业趋势。广义的数据科学涵盖利用各类工具、算法理解数据蕴藏含义的全过程,机器学习可以视为其中的一种方式和手段;狭义的数据科学也可以仅指代机器学习的前置步骤,包括准备、预处理数据并进行探索性分析等。正如我们从报吿《人工智能十年展望(八):探索ChatGPT根基——数据与人工智能如何相互成就?》开始一直强调的观点,数据和AI一体两翼,数据是模型的起点、且一定程度上决定了模型的最终效果和质量,数据基础设施厂商卡位关键,从Data向AI布局是技术能力和业务逻辑的自然延伸。LLM等大模型的渗透发展不仅额外增加了数据平台上AI相关的工作流负载,还可以带动底层Data基础设施的需求。
模型训练:模型库更加刚需,训练框架持续迭代,软件工具协助实验管理
大模型具有一定通用性,开发者们可以“站在巨人的肩膀上”,在预训练模型的基础上通过少量增量训练蒸馏出专精的小模型以解决垂类场景的需求。LLM带来的新变化主要包括:1)要想高效便捷地获取模型,则需要一个集成托管各类模型的社区也即模型库;2)催生更适应LLM大规模训练需求的底层分布式计算引擎和训练框架。此外,模型训练过程涉及多次往复的修改迭代,无论是ML还是LLM都需要借助实验管理工具进行版本控制和协作管理。
模型库(Model Hub):把握从数据到模型的工作流入口。模型库顾名思义是一个托管、共享了大量开源模型的平台社区,供开发者下载各类预训练模型,除模型外,主流的Model Hub平台上还同时提供各类共享的数据集、应用程序Demo等,是AI、ML细分领域的“GitHub”。典型代表厂商包括海外的Hugging Face、Replicate,国内关注Gitee(开源中国推出的代码托管平台)和ModelScope(阿里达摩院推出的AI开源模型社区)等项目。在商业模型上,Model Hub厂商一般选择切入下游的AutoTrain(自动创建、优化、评估模型)或模型推理服务,也在尝试就Model Hub功能收取订阅制会员费用。
图表12:Hugging Face上托管了NLP、机器视觉等各类模型
资料来源:Hugging Face官网,中金公司研究部
分布式计算和深度学习框架:大模型“炼丹炉”。分布式计算引擎方面,LLM的训练过程需要大规模的GPU分布式计算集群,过去大数据已带动了以MapReduce、Spark为代表的分布式计算引擎的发展,但以Ray为代表的近年在AI大潮下兴起的分布式计算框架则更贴合AI需求(Ray的首篇论文名为《Ray: A Distributed Framework for Emerging AI Applications[7]》),其核心模块Ray Tune、Ray Rllib、Ray Train分别对应机器学习调参、强化、深度学习调参的流程。Ray在官网的用户案例中表示“Ray是使OpenAI能够增强其训练ChatGPT和类似模型能力的关键”[8]。此外,Ray作为更底层的分布式计算引擎,和TensorFlow、PyTorch等深度学习框架兼容,而DeepSpeed、ColossalAI等则是在PyTorch等基础框架之上针对LLM的优化训练设计的新一代框架。
实验管理:记录实验元数据,辅助版本控制,保障结果可复现。模型训练是一种实验科学,需要反复的修改与迭代,同时由于无法提前预知实验结果往往还涉及版本回溯、多次往复,因此模型的版本控制和管理就较为必要,实验管理软件可以辅助技术人员和团队追踪模型版本、检验模型性能。该领域代表厂商为Weights and Biases(W&B)和Neptune,跟踪机器学习实验,记录实验元数据,包括训练使用数据集、框架、进度、结果等,支持以可视化的形式展现结果、多实验结果对比、团队协作共享等。此外,实验管理也是LLMOps/MLOps平台型产品如星环科技Sophon、Google Vertex AI等产品中的重要模块之一。
图表13:以Neptune为例,记录每次实验的元数据,支持多实验结果对比
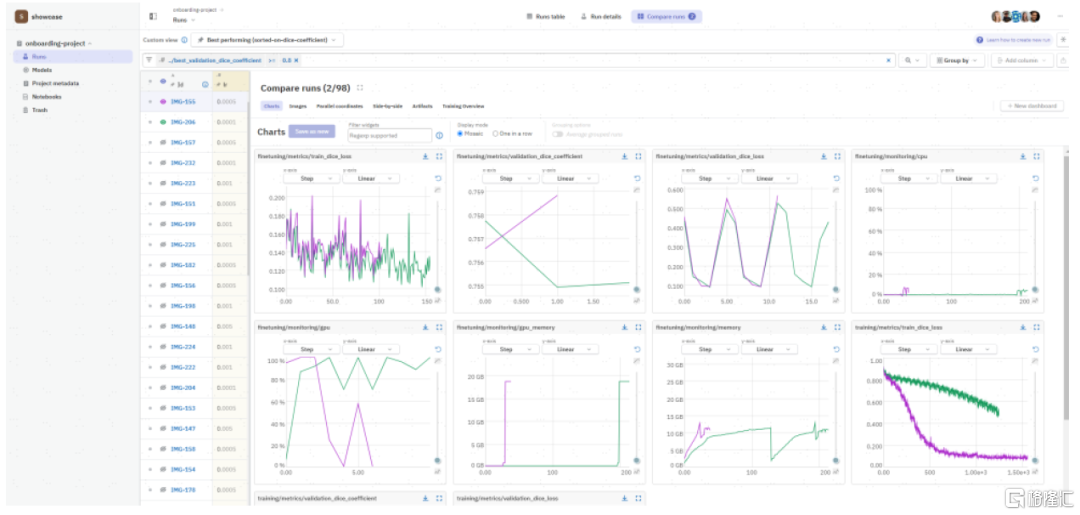
资料来源:Neptune官网,中金公司研究部
模型部署:更多模型从实验走向真实业务环境,部署和监控需求提升
模型部署是让模型从实验环境走向真实生产环境的重要环节,借助模型部署工具能够解决模型框架兼容性差的问题并提升模型运行速度。模型监控通过对模型输出结果和性能指标的追踪,保障模型上线后的可用性。我们认为,过去由于ML模型的非标和项目制,大规模、持续性的模型部署和监控需求未被完全激发出来,LLM模型端的突破释放出大规模应用落地的潜能,更多的模型从实验环境走向生产环境,我们认为有望整体提振模型部署和监控的需求。
模型部署:从实验走向生产的重要环节。模型部署指把训练好的模型在特定环境中运行,需要尽量最大化资源利用效率,保证用户使用端的高性能。模型部署领域参与者较多,比如Ray、Tensorflow、PyTorch等训练框架都提供配套的模型部署功能,模型库厂商如Hugging Face、实验管理厂商如W&B也有相关产品,此外还有如Seldon、BentoML、OctoML等独立项目/产品。和训练框架自带的部署模块相比,三方的综合性产品能够为不同框架下训练出来的模型提供一套相对统一的部署方式。以Seldon为例,在复杂的多模型推理场景下,Seldon通过模型可解释性、异常值检测等模块,最终选出表现最好的模型进行结果反馈。
图表14:Seldon支持的单一模型、复杂多模型的推理过程示意
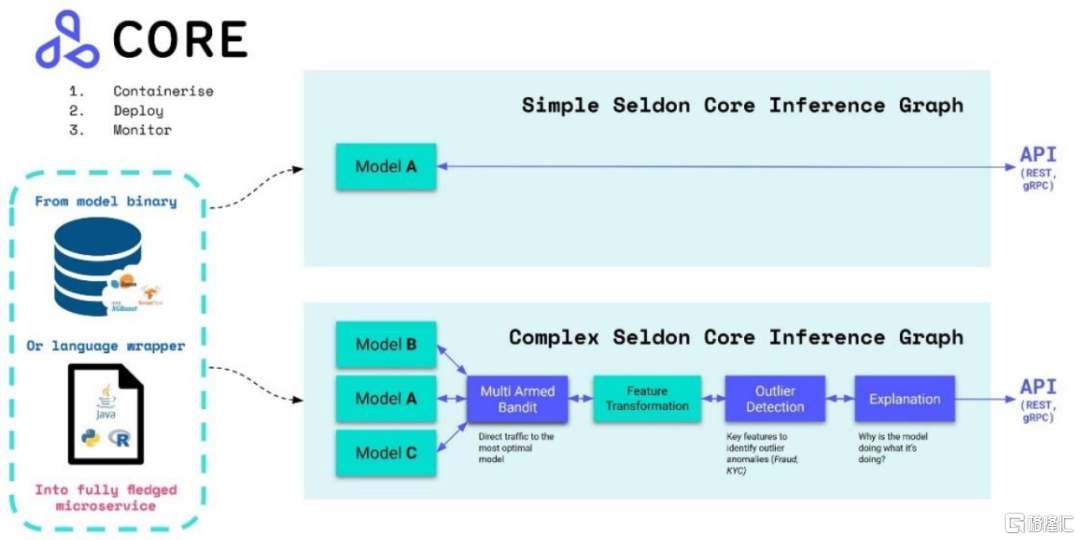
资料来源:Seldon官网产品文档,中金公司研究部
模型监控:模型可观测性保障可靠可用。可观测性在传统IT系统运维中就是重要的数智化手段之一,通过监控各类机器、系统的运行数据对故障和异常值提前吿警。模型监控同理,监测模型上线后的数据流质量以及表现性能,关注模型可解释性,对故障进行根因分析,预防数据漂移、模型幻觉等问题。模型可观测性领域有较多创业公司,包括Fiddler、WhyLabs、Evidently AI等,实验管理厂商如W&B、模型部署厂商如Seldon也有所涉及,此外,传统的IT运维可观测性厂商也有机会切入AI模型监控领域,海外如Datadog已经尝试将Open AI的模型服务加入纳管范畴,我们也建议关注国内相关厂商的后续进展。
图表15:以WhyLabs为例看模型可观测性在工作流中的具体环节定位
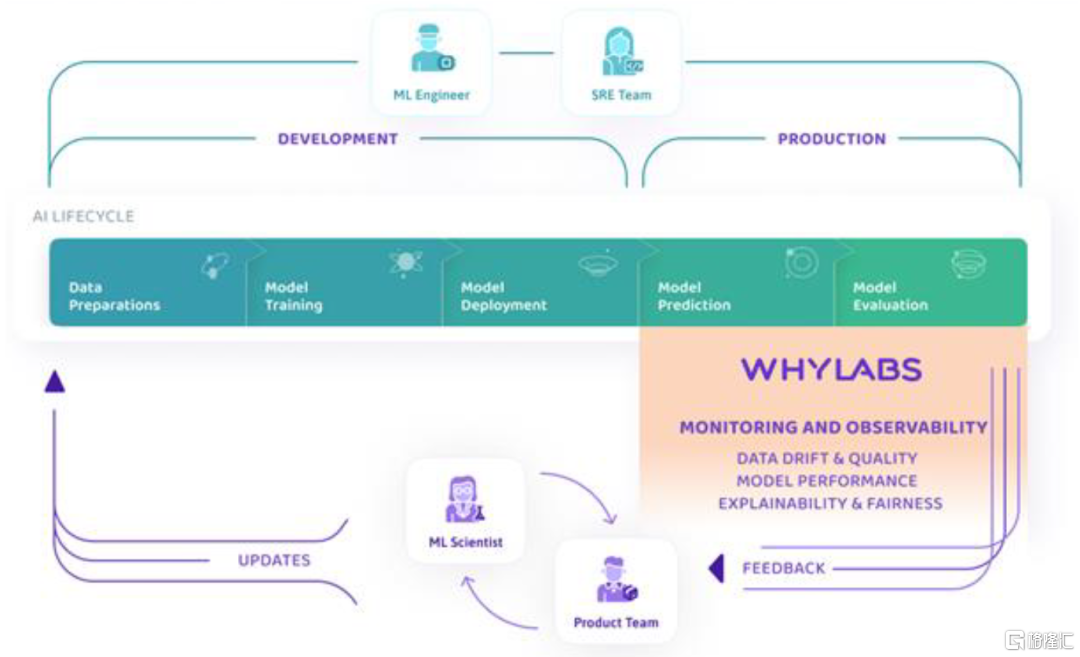
资料来源:WhyLabs官网产品文档,中金公司研究部
应用整合:催生向量数据库和应用编排框架新需求
正如前文提及,LLM模型端的突破释放出更多应用落地的潜能,由此催生出对应用产品整合相关工具产品的需求,其中较为关键的是向量数据库和LLM应用编排工具。
向量数据库:LLM的外部知识库。让通用大模型具备专业知识主要有两种途径,一是通过微调将专有知识内化到LLM中;另一种则是利用向量数据库给LLM增加外部知识库,后者成本更低。向量数据库和LLM的具体交互过程为:用户首先将企业知识库的全量信息通过嵌入模型转化为向量后储存在向量数据库中,用户输入prompt时,先将其同样向量化,并在向量数据库中检索最为相关的内容,再将检索到的相关信息和初始prompt一起输入给LLM模型,以得到最终返回结果。
向量化技术本身已较为成熟,海外模型如Word2Vec、FastText等,国内中文Embedding模型有MokaAI开源的M3E、IDEA CCNL[9]开源的二郎神系列。向量数据库厂商/产品主要包括Pinecone、Zilliz、星环科技Hippo等,另外也有传统数据库、大数据平台厂商如PGSQL、Databricks通过增加向量查询引擎插件来实现支持。我们认为,向量数据库是AI Answers类应用落地的刚需,同时本土厂商在中文Embedding方面可能更具优势。
图表16:向量数据库和LLM的具体交互过程
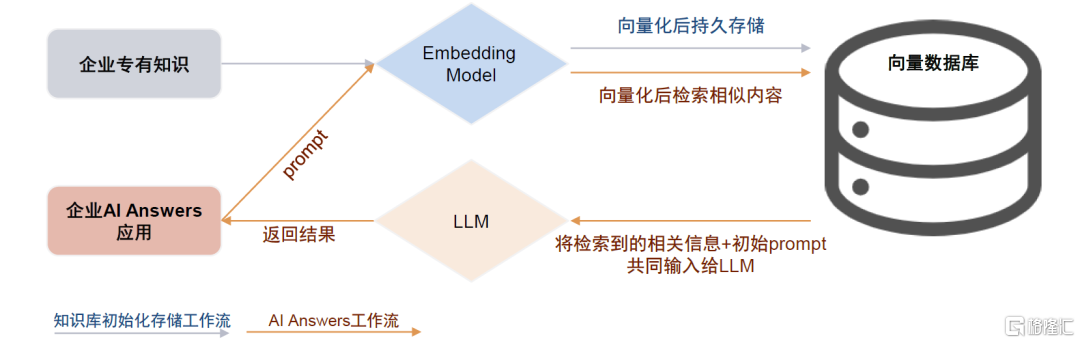
资料来源:Pinecone官网,星环科技公众号,中金公司研究部
应用编排框架:LLM应用“粘合剂”。LLM应用编排框架是一个封装了各种大语言模型应用开发所需逻辑和工具的代码库,LangChain是当下最流行的框架之一,还有Anarchy、Dust、AutoGPT、LlamaIndex等。初始化的大模型存在无法联网、无法调用其他API、无法访问本地文件、对Prompt要求高、生成能力强但内容准确度无法保证等问题,应用编排框架提供了相应功能模块,帮助实现从LLM到最终应用的跨越。以LangChain为例,它主要包含以下几个模块:1)Prompt实现指令的补全和优化;2)Chain调用外部数据源、工具链;3)Agent优化模块间的调用顺序和流程;4)Memory增加上下文记忆。
集成开发环境:交互式Notebook逐渐流行。在上述AI建模流程中,开发者需要处理大量代码编写、分析、编译、调试等工作,可以直接在对应环节或平台型产品的内置环境中进行,也可以使用专门的集成开发环境并调取所需功能。其中,Notebook是一种交互式的开发环境,和传统的非交互式开发环境相比,Notebook可以逐单元格(Cell)编写和运行程序,出现错误时,仅需调整并运行出现错误的单元格,大大提升开发效率,因此近年逐渐流行、深受数据科学家和算法工程师的喜爱,被广泛应用于AI算法开发训练领域。
点工具不断拓宽产品边界,LLMOps一站式解决方案或更适应国内市场
点工具厂商正不断拓宽能力边界。前文我们详细介绍了模型训练、构建应用工作流涉及的主要环节及各环节点工具厂商,事实上,这些点工具厂商在强项环节之外亦不断拓宽产品能力边界,比如数据标注厂商Scale AI拓展合成数据业务并正在投入LLMOps领域的Scale Spellbook(做一个基于大语言模型的开发者工具平台);模型库厂商Hugging face切入AutoTrain和模型部署;实验管理厂商W&B切入模型部署和模型监控等。
MLOps/LLMOps提供一站式平台解决方案,可及市场空间更大,多采取Data+AI一体化战略。除点工具外还有平台型的MLOps/LLMOps产品,基本涵盖了上述流程的主要环节,大型科技企业、数据基础软件厂商均参与其中。我们认为,基于整体数字化进程和软件付费意愿习惯判断,海外企业客户可能倾向于选取点工具自组工具栈,而国内客户可能倾向于一站式的解决方案。此外,从目前AI Infra领域独角兽的估值水平来看,平台型厂商多采取Data+AI一体化战略,起步较早、规模天花板更高。
图表17:AI Infra领域独角兽企业一览

注:统计截至2023年7月,最新估值截至各公司最近一次融资 资料来源:Crunchbase,中金公司研究部
求索:海外重点项目及公司一览
(Scale、Hugging Face、Weight & Biases、Pinecone、Databricks、C3.AI)
数据准备:Scale
数据标注是核心业务,AI辅助或能降低人工参与比例。Scale从自动驾驶领域的标注起家,自动驾驶之后,公司的订单还来自政府、电商、机器人、大模型(RLHF)等领域,对应着过去几年AI行业的趋势。目前公司支持地图、商品目录、图像、视频、文档、音频等各类数据的标注,按标注量计价,比如Scale lmage起价为每张图片2美分、每条标注6美分。数据标注产业较为依赖人力,但公司也在训练标注算法通过AI辅助降低人工参与比例。Open AI、Stability、Co:here等领先的生成式AI厂商均为公司客户。
积极布局LLMOps领域,推出企业级生成式AI平台产品。顺应大模型趋势,Scale推出了LLMOps应用开发平台工具Scale Spellbook,用户仅需上传数据、编辑指令,并可以直接比较、微调不同prompt、不同LLM的效果,快速构建智能问答、总结、生成、分类等功能的LLM应用。结合数据标注和LLMOps能力,Scale能提供一整套企业AI应用开发解决方案。
图表18:Scale AI的产品布局一览和企业级生成式AI平台方案
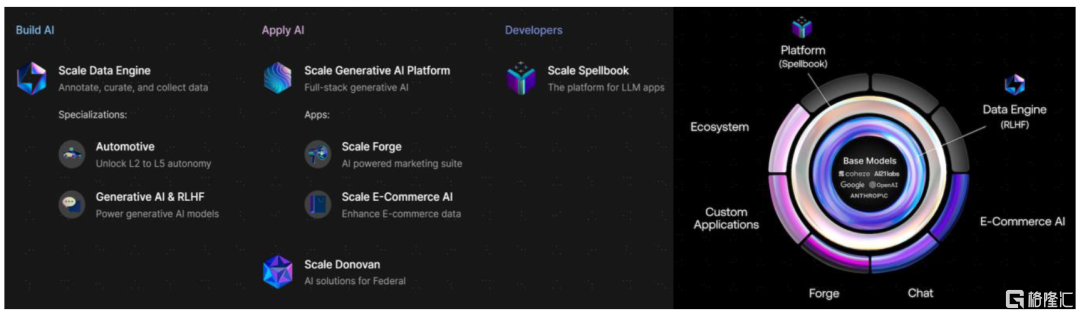
资料来源:Scale官网,中金公司研究部
模型训练:Hugging Face
Hugging Face是当前最流行的AI/ML社区平台之一。LLM浪潮下,Hugging Face凭借高质量的Transformers模型库和社区受到关注。用户可以在Hugging Face上托管和共享ML模型、数据集、应用程序Demo,也可以直接基于平台构建、训练和部署模型。截至7月底,Hugging Face上有超过26万个预训练模型,是ML领域的“Github”,超过5千家机构正在使用。
Hugging Face卡位关键,切入下游MLOps探索变现。商业化层面,Hugging Face推出了个人和企业会员,个人会员每月9美元,在推理API和AutoTrain功能上享有优先级;企业版收费20美元/月/用户,覆盖整合了模型实验、自动训练、应用测试、最终上线部署等功能环节,同时提供更多企业级安全方面的支持。此外,AutoTrain(用户仅需定义创建任务并上传数据,系统自动选择模型并训练)、应用测试、模型推理功能亦支持单独根据使用的硬件资源按用量收费。
图表19:Hugging Face可以托管共享ML模型、数据集,也可以构建、训练和部署模型

资料来源:Hugging Face官网,中金公司研究部
模型训练&部署:Weight & Biases
Weights & Biases成立于2017年,从实验管理到MLOps全生命周期。W&B创立灵感来源于创始人在OpenAI的一次实习经历,初衷是希望研发一款方便AI/ML团队协同的工具。因此W&B从模型实验管理环节起家,并延伸至对数据准备、模型训练和模型部署全生命周期的管理,为技术人员提供追踪模型版本、检验模型性能的功能,帮助其选择最优版本的模型进行上线。官网最新显示,目前其平台产品包含10大功能模块,在实验追踪、协作可视化、模型版本管理、超参调节基础功能之外,新增了ML工作流自动化、模型监控、LLM提示词工程、ML应用开发环境等。
W&B支持云和本地化部署,从定价看,Personal方案免费,只对个人用户开放;Starter方案针对10人以下的小团队,按照模型训练时间范围收取每用户每月50-150美元不等的费用;Enterprise方案针对10人以上的公司、定制化报价。作为MLOps模型管理赛道中的翘楚,公司受益于大模型发展红利高速增长,OpenAI、DeepMind等都是其客户。公司于2021年10月完成C轮融资,融资1.35亿美元,估值超过10亿美元。
图表20:W&B产品拥有十大功能模块,覆盖机器学习全流程

资料来源:Weights & Biases官网,中金公司研究部
应用整合:Pinecone
商业化向量数据库的领先实践。Pinecone的CEO Edo Liberty曾在AWS领导Sagemaker产品,而后担任亚马逊AI Lab的负责人。在亚马逊期间,Edo观察到很多公司运用ML的难点不在于训练或部署模型,而在于实时处理海量的向量数据,由此萌生创业念头。2021年初Pinecone公司正式成立。Pinecone在成立之初就确立了闭源商业化的运营思路,按照存储0.025美元每个月每GB,计算每小时0.1 - 1美元不等收费。目前Pinecone是海外最流行的向量数据库之一,我们观察到在大多数ML工作流上下游厂商官网的适配名单中都有Pinecone的身影,在海外逐渐形成了“OpenAI+Pinecone”的AI应用开发技术栈共识。
Data+AI:Databricks
Databricks提供全球领先的数据科学计算分析平台,强调以数据为中心的机器学习模式。Databricks是Spark官方发行版的开发公司,提供一体化的数据湖仓平台产品,实现对海量结构及非结构化数据的存储、分析,并重视平台对数据科学、机器学习等AI相关工作流的支持,直接提供Machine Learning平台产品,涵盖数据准备、模型训练到模型投入生产的全流程,此外,Databricks还在2018年开发并开源了MLOps工具链项目MLflow,也是其ML平台的重要能力组件之一。
今年6月底召开的峰会上发布多项Data+AI技术进展。1)生成式AI相关进展主要集中在自然语言交互、AI应用开发工具链两方面:Databricks发布SDK for Spark、LakehouseIQ,实现开发、查询、检索等场景的自然语言交互;发布Lakehouse AI旨在更高效便捷地组织AI应用开发工作流。2)数据管理平台基础能力亦持续迭代:Databricks发布UniForm存储格式与Hudi、Iceberg互通等。自研之外,Databricks亦通过收购扩大能力圈,近期AI相关交易频繁。
国内AI Infra相关厂商巡礼
星环科技:Data+AI平台型厂商
提供完整大模型工具链、发布向量数据库,助力企业打造垂类大模型、开发专属AI应用。今年5月底公司举办技术峰会,并发布了多项Data+AI产品进展。Sophon LLMOps是在公司原有的Sophon MLOps平台基础之上,针对大语言模型及其衍生数据、模型、应用问题进行相应功能增强后的大模型开发运维一站式工具链,赋能企业客户微调垂类领域专属大模型。同时,星环推出自研的企业级分布式向量数据库Hippo,支持存储、索引、管理海量向量式数据集,为大模型补充实时、变化、专有领域的知识信息并能解决输入token数量有限的问题,拓展大模型的时间和空间维度,赋能企业客户构建基于大模型的个性化应用。除工具外,星环计划推出两个自研行业垂类大模型。
图表21:基于星环产品栈的企业自有大模型应用构建流程示意图
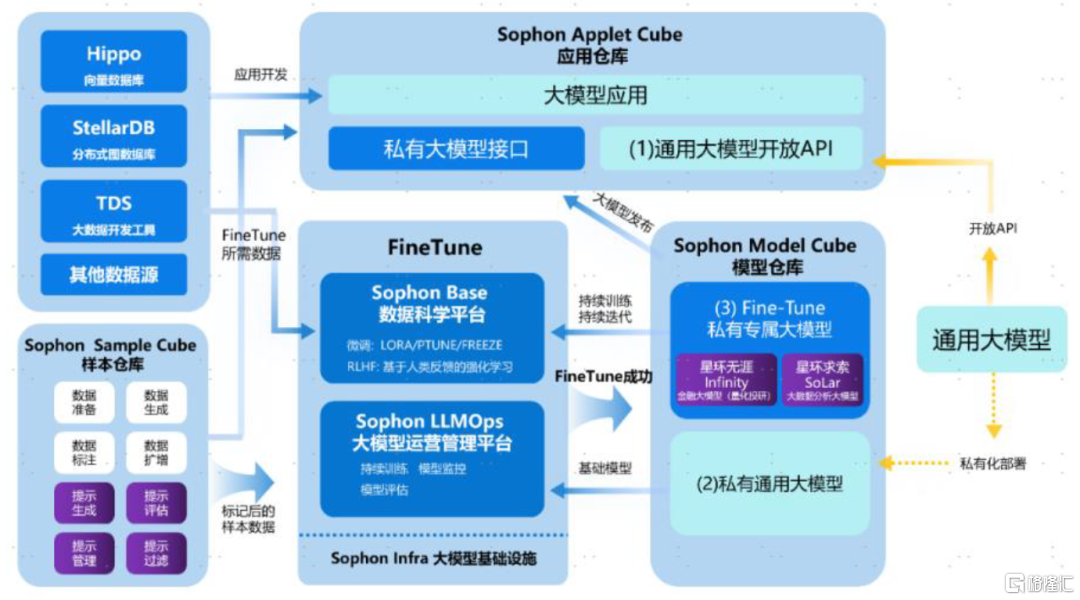
资料来源:WAIC大会,星环科技公众号,中金公司研究部
第四范式(未上市):人工智能解决方案供应商,发布企业级类GPT产品
第四范式致力于为企业提供以平台为中心的AI解决方案。授人以鱼不如授人以渔,除了提供AI业务应用之外,第四范式为企业自行机器学习模型开发场景提供了企业级AI操作系统4Paradiagm AIOS和人工智能机器学习平台HyperCycle。LLM趋势下推出企业级类GPT产品“式说”,助力企业利用内部知识解决问题。第四范式通过将类GPT语言模型与垂直领域知识进行融合,推出“式说”产品,旨在解决大型生成式语言模型在企业内部使用场景下的局限,满足企业场景下的AIGC需求。“式说”主打三大产品特点:1)数据安全,通过私有化部署解决企业客户对数据安全的顾虑;2)内容可信,“式说”基于企业内部数据库,并且在提供回答时标注信息原始出处,增加了回答的可信性和可靠性;3)成本可控,“式说”算力成本相对可控,对数据标注量的需求较小。
图表22:机器学习平台HyperCycle的三个子产品
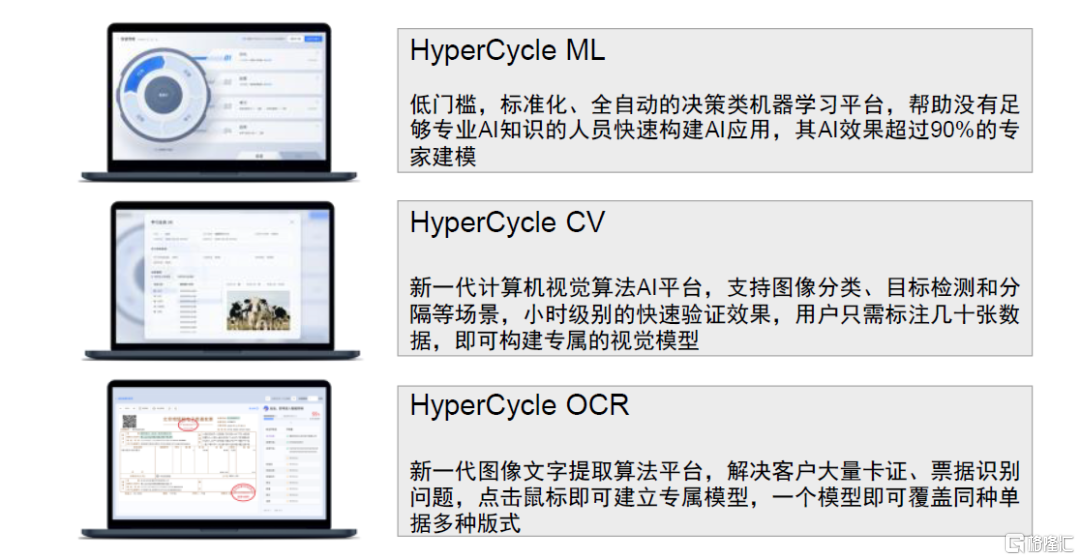
资料来源:第四范式官网,中金公司研究部
图表23:第四范式“式说”产品工作界面
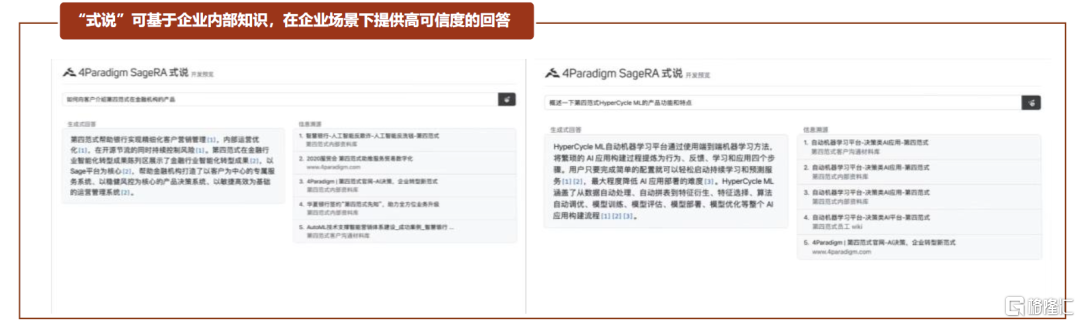
资料来源:第四范式公司官网,中金公司研究部
云知声(未上市):发布山海大模型,赋能医疗等垂类场景
山海大模型发布,模型兼具通用能力与行业落地能力。云知声成立于2012年,是中国AGI技术产业化的先驱之一,2016年开始建立Atlas人工智能基础设施,并据此开发了拥有600亿个参数的专有大模型山海大模型,于2023年5月正式发布。山海大模型通用能力包括语言生成、语言理解、知识问答、推理能力、数学能力、代码能力和安全合规能力;落地能力包括插件扩展、领域增强和企业定制,并支持企业私有化部署。
山海大模型可以从多个场景进行赋能,医疗是标杆赛道。云知声选择的垂类包括智慧医疗(手术记录撰写助手、门诊病历撰写助手)、商保智能理赔系统、云贝销售管理系统、山海知识管理系统(企业服务通用管理)、教育(山海AI口语)和智慧物联(智能物业管家,贴心生活助手),应用具备横向拓展性。
图表24:云知声山海大模型能力概览

资料来源:云知声山海大模型发布会,中金公司研究部
九章云极(未上市):机器学习平台供应商
九章云极定位人工智能基础软件供应商。九章云极成立于2013年,专注数据科学平台的研发,提供机器学习建模能力、自动机器学习(AutoML)能力和实时数据计算能力。目前其核心产品主要有DataCanvas APS,是集数据准备、特征工程、算法实现、模型开发、模型发布、模型生产化管理于一体的机器学习平台;和DataCanvas RT,支持分布式流数据实时处理,能够将多种数据流接入实时处理并分析,将ETL、业务模型、机器学习、人工智能、可视化扩展到实时的大数据产品。
创新奇智:领先的“AI+制造”解决方案供应商,推出AInnoGC
企业级AI解决方案供应商,专注于“AI+制造”领域。创新奇智自研的“MMOC人工智能技术平台”具有深度学习能力,支持自动化、低代码技术开发,以及“云、边、端”一体化部署交付,能端到端支持AI解决方案创新、研发和交付。同时,公司2018年成立以来聚焦于AI+制造领域,根据IDC数据[10],2022年创新奇智位居中国工业数据智能市场领导者象限,连续3年位居中国第二大AI工业质检厂商。创新奇智推出以工业预训练大模型为核心的AIGC引擎奇智孔明AInnoGC。AInnoGC具有:1)适合工业场景的基础大模型;2)完善的企业级Fine Tune机制和Prompt工程支持;3)丰富的API/SDK和MaaS服务等产品特征。
汉得信息(未覆盖):基于汉得融合中台HZERO,发布AIGC中台
发布AIGC中台,打造汉得AI知识、智慧交互平台。汉得基于融合中台HZERO,着手打造AIGC中台,预置“百模”对接和大量AIGC通用应用功能,并提供低代码AIGC应用编排工具。具体组件来看,构建AIGC中台-知识库组件,帮助企业更便捷地应用AIGC知识问答能力;提供智慧交互助手,预置语音、数据查询、业务处理等能力,提供一个企业“AI助手”基础版本,降低在各业务场景下构筑AIGC应用的难度。
万达信息(未覆盖):自研AI中台,和华为盘古合作打造行业垂类大模型
自研AI科技中台、参与制定MLOps能力成熟度模型。2022年的人工智能大会上,公司发布了AI科技中台,提供AI模型训练和应用开发、部署、运维的全生命周期管理服务。此外,公司还参与制定全国首个AI模型开发管理标准《人工智能研发运营一体化(Model/MLOps)能力成熟度模型》系列标准[11]。面向智慧城市、医疗衞生等行业研发AI场景与平台,与华为盘古合作打造行业大模型。万达信息基于传统主业政务信息化、医疗信息化等行业know-how结合AI能力,形成了数百项行业人工智能算法模型及多项AI解决方案与产品。此外,今年7月,公司与华为云签署合作协议[12],计划基于盘古大模型打造智慧城市、医疗健康垂类行业大模型,推动城市数字化转型。
软通动力(未覆盖):天璇MaaS平台持续迭代,和百度、华为大模型合作
软通天璇MaaS平台迭代至2.0版本。软通天璇2.0是基于升思MindSpore人工智能框架打造的包含大模型技术底座、行业大模型及管理、场景大模型应用以及大模型一站式运营服务、数据治理和安全服务五要素的MaaS平台。与百度、华为云达成战略签约,共筑大模型产业化落地。今年7月,软通动力和百度正式签订战略合作协议[13],推动文心千帆大模型平台与软通天璇2.0 MaaS平台的互补优势,共建面向工业、能源、制造、金融等多行业、多领域的智能应用。同月,软通动力与华为云签约,成为盘古大模型的垂域模型标注训练、服务交付、应用解决方案和升腾迁移领域的合作伙伴,并计划共同打造保险行业大模型。
海天瑞声(未覆盖):国内领先的数据标注厂商
海天瑞声是国内领先的数据标注厂商。通过设计数据集结构、组织数据采集、对取得的原料数据进行加工,形成可供AI算法模型训练使用的专业数据集,并以软件形式向客户交付。公司所提供的训练数据涵盖智能语音、计算机视觉、自然语言等领域,服务于人机交互、智能家居、智能驾驶、智慧金融、智能安防等应用场景。公司公吿披露,截至2022年底,公司客户累计数量810家,覆盖科技互联网、社交、IoT、智能驾驶、智慧金融、教育科研以及部分政企机构,包括阿里巴巴、腾讯、百度、科大讯飞、海康威视、字节跳动、微软、亚马逊、三星、中国科学院、清华大学等。
Gitee(未上市):开源中国旗下代码托管及DevOps平台
开源中国旗下代码托管及DevOps平台。开源中国(Open Source China,OSC)是国内的一个开源技术社区,成立于2008年,官网数据显示目前OSCHINA有600万活跃开发者[14]。2013年,OSCHINA建立了代码托管与DevOps平台“码云 Gitee”,为广大开发者提供团队协作、源码托管、代码质量分析、代码评审、测试、CI/CD与代码演示等功能,官网数据显示目前Gitee社区开发者超过1,000万,托管项目超过2,500万,汇聚几乎所有本土原创开源项目[15],并于2016年推出企业版。
风险
技术进展不及预期:人工智能作为前沿新兴技术,仍处于技术的快速发展期,其进展有一定的不确定性,若技术进展不及预期,可能导致产业化进展缓慢。
应用落地不及预期:应用及商业化落地是人工智能能否顺利走向下一阶段的关键点,若国内应用及商业化落地节奏不及预期,对人工智能的进展将带来负面影响。
行业竞争加剧:人工智能是产业的热点,未来商业价值显著,科技巨头、初创公司均在此领域布局,未来垂类及应用层的行业竞争可能会进一步加剧。
[1]https://arxiv.org/pdf/2303.08774.pdf 《GPT-4 Technical Report》(OpenAI,2022)
[2]https://arxiv.org/pdf/2303.08774.pdf 《GPT-4 Technical Report》(OpenAI,2022)
[3]https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
[4]https://arxiv.org/pdf/2304.02643.pdf 《Segment Anything》(Alexander Kirillov等,2023)
[5]《Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning》(Pablo Villalobos等,2022);https://arxiv.org/pdf/2211.04325.pdf
[6]https://www.statice.ai/post/types-synthetic-data-examples-real-life-examples
[7]https://arxiv.org/pdf/1712.05889.pdf 《Ray: A Distributed Framework for Emerging AI Applications》(Philipp Moritz等,2018)
[8]https://docs.ray.io/en/releases-2.4.0/ray-overview/use-cases.html
[9]全称为IDEA研究院认知计算与自然语言研究中心
[10]https://mp.weixin.qq.com/s/WYGs59rNYz-EgxQLupO_GQ
[11]https://www.wondersgroup.com/05161643118326.html
[12]https://www.wondersgroup.com/07101657518645.html
[13]https://mp.weixin.qq.com/s/h0IYFNptWHwhUhLvGZcy-Q
[14]https://www.oschina.net/home/aboutosc
[15]https://gitee.com/about-us
注:本文摘自中金公司2023年8月8日已经发布的《人工智能十年展望(十二):详解大模型时代的基础软件堆栈AI Infra》,分析师:
韩蕊 分析员 SAC 执证编号:S0080523070010
于钟海 分析员 SAC 执证编号:S0080518070011 SFC CE Ref:BOP246
胡安琪 联系人 SAC 执证编号:S0080122070070
王之昊 分析员 SAC 执证编号:S0080522050001 SFC CE Ref:BSS168
魏鹳霏 分析员 SAC 执证编号:S0080523060019 SFC CE Ref:BSX734